-1 注意事项
【这些是我配置的问题?】
真相!(9.28)
所有问题都归结为虚拟机的ip地址发生改变
解决方案:
重新在终端使用命令:ip a(还是ip_a?)
- 远程链接虚拟机的时候,本地的ip不要改变(比如更改代理【还有更改wifi?】
不然就会出现无法连接到虚拟机的报错 - 远程连接虚拟机的时候,虚拟机不能处于休眠状态
- Rocky Linux是CentOS的版本,安装open mpi 的时候有命令字符的差别
0 程序的运行
建立在环境以及虚拟机已经配置好的基础上
首先链接虚拟机,注意,一定要在连接网络的基础上进行,否则可能会报错无法连接虚拟机(好奇怪?)
然后打开文件夹,注意,直接点最上面的…,然后加载计算机(还是虚拟机)上面的所有文件
然后打开terminal
然后最重要的是,在终端先输入# cd home
然后输入# ls
接下来输入# cd SRQ
最后输入运行指令# sh run.sh
1 阅读解释文档
1.1 用GPT询问solve.cpp里面程序的含义
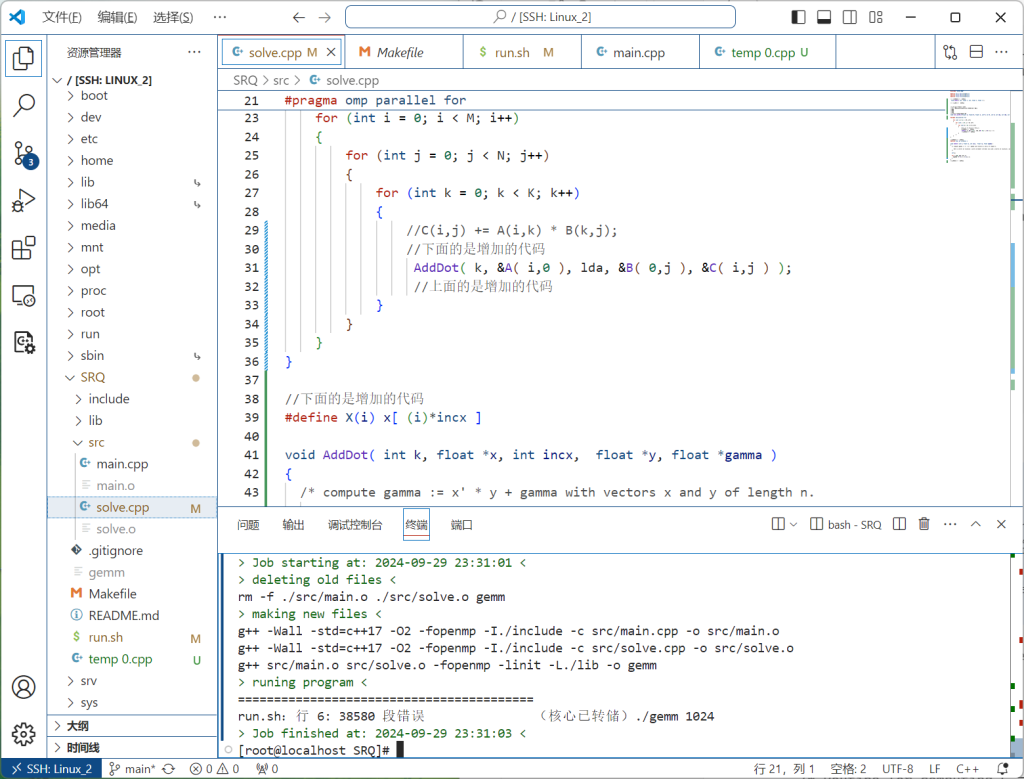
这个代码实现了一个矩阵乘法的简单实现,下面是代码的逐步解释:
[!note]
- 宏定义?
- 计算的过程似乎没问题,不需要去优化?
- 偏移量?(不管,是矩阵计算中涉及到的,和优化应该没关系【但是后面学到矩阵计算的代码实现的时候可以留一下这个】)
- GPT总结中的“传统的三重循环矩阵乘法”,是不是意味着这个矩阵计算的方法也可以优化?
- 在学长的直播演示中引用了“一坨”代码,然后运行就快了很多,后面可以往这方面想,接下来可以去了解下那一坨东西是什么
基本概念:
矩阵乘法的基本原理是:
- 如果有矩阵 ( A )(尺寸 ( M \times K ))和矩阵 ( B )(尺寸 ( K \times N )),矩阵乘法的结果 ( C ) 会是一个尺寸 ( M \times N ) 的矩阵。
- 对于 ( C ) 矩阵中的每个元素 ( C(i,j) ),它的值是 ( A ) 的第 ( i ) 行和 ( B ) 的第 ( j ) 列对应元素的点积。
代码详细解析:
#define A(i,j) A[(i)*lda+(j)]
#define B(i,j) B[(i)*ldb+(j)]
#define C(i,j) C[(i)*ldc+(j)]- 这三行宏定义用于方便矩阵元素的访问。假设矩阵 ( A ), ( B ), 和 ( C ) 是存储在一维数组中的,那么通过这些宏定义可以像访问二维数组一样访问矩阵元素。
A(i,j)表示访问矩阵 ( A ) 中第 ( i ) 行、第 ( j ) 列的元素。实际上是通过一维数组计算位置:A[i * lda + j]。其中lda是矩阵 ( A ) 的列数,即列的步长。- 同理,
B(i,j)和C(i,j)用于访问矩阵 ( B ) 和 ( C ) 中的元素。
矩阵乘法的主循环:
void User_matMult(float* A, float* B, float* C, int M, int K, int N, int lda, int ldb, int ldc){
for (int i = 0; i < M; i++)
{
for (int j = 0; j < N; j++)
{
for (int k = 0; k < K; k++)
{
C(i,j) += A(i,k) * B(k,j);
}
}
}
}float* A, float* B, float* C:指向矩阵 ( A ), ( B ), 和 ( C ) 的指针。它们实际上是通过一维数组存储的矩阵。int M, int K, int N:代表矩阵的维度:- ( M ):矩阵 ( A ) 和 ( C ) 的行数。
- ( K ):矩阵 ( A ) 的列数和矩阵 ( B ) 的行数。
- ( N ):矩阵 ( B ) 和 ( C ) 的列数。
int lda, ldb, ldc:分别代表矩阵 ( A ), ( B ), 和 ( C ) 的列步长(列的宽度)。这是矩阵在内存中的存储方式,每行的偏移量是通过i * lda来计算的。
核心计算部分:
- 外层循环 (
for (int i = 0; i < M; i++)):
- 这表示遍历矩阵 ( C ) 的每一行。
- 中间层循环 (
for (int j = 0; j < N; j++)):
- 这表示遍历矩阵 ( C ) 的每一列。
- 对于每个元素 ( C(i, j) ),它需要计算 ( A ) 的第 ( i ) 行和 ( B ) 的第 ( j ) 列的点积。
- 内层循环 (
for (int k = 0; k < K; k++)):
- 这是矩阵乘法的核心步骤,用于计算 ( A ) 的第 ( i ) 行和 ( B ) 的第 ( j ) 列的点积。具体是将 ( A(i,k) ) 和 ( B(k,j) ) 的乘积累加到 ( C(i,j) ) 中。
- 具体来说,( C(i,j) += A(i,k) * B(k,j) ) 表示不断累加 ( A(i,k) ) 和 ( B(k,j) ) 的乘积。
矩阵乘法流程:
- 初始化:矩阵 ( C ) 中的所有元素初始为 0。
- 遍历矩阵 ( A ) 和矩阵 ( B ):
- 对于 ( C(i,j) ) 来说,它是通过遍历 ( A(i,k) ) 和 ( B(k,j) ) 的乘积累加得到的。
- 存储结果:最终计算的结果会存储在矩阵 ( C ) 的相应位置。
总结:
- 该代码实现了传统的三重循环矩阵乘法。对于每个结果矩阵 ( C(i,j) ),计算时会累加矩阵 ( A ) 的第 ( i ) 行与矩阵 ( B ) 的第 ( j ) 列的点积。
- 代码使用了一维数组来表示矩阵,并通过
lda,ldb,ldc参数控制步长,适应了实际应用中常见的矩阵存储方式。
1.2 对比bese与sovle里面的代码差异
1.2.1#include “solve.hpp”
[!note]
内容:
copy另一个文件内的代码
copy的文件和此文件都必须在同一个项目内
#include "solve.hpp" 是一个预处理指令,用于在编译前将 solve.hpp 文件的内容包含到当前的源代码文件中。
具体解释:
#include预处理指令:
- 这是 C/C++ 中的一个指令,告诉编译器在编译当前文件之前,把指定的头文件(header file)的内容插入到这个位置。
- 它相当于把
solve.hpp文件中的代码复制到#include "solve.hpp"的位置上。
"solve.hpp":
- 引号
"表示引用当前项目或自定义的头文件,而不是标准库中的头文件。编译器会在当前项目的目录中查找这个文件。 .hpp是 C++ 头文件的常见扩展名,通常用于声明函数、类和变量的接口(但不包含它们的具体实现)。在这个文件中,通常会有函数的声明,而实际的实现代码可能在solve.cpp中。
头文件的作用:
- 头文件的主要作用是声明函数、类、结构等,这些声明允许多个源文件共享同样的接口,而具体的实现则通常位于
.cpp或.c文件中。 - 例如,
solve.hpp中可能包含一些函数的声明,例如User_matMult,而这些函数的具体实现是在solve.cpp文件中。
在这个代码中,solve.hpp 可能包含了与矩阵乘法相关的函数声明、常量、宏定义等,供 main.cpp 文件使用。
例子:
假设 solve.hpp 文件中包含以下内容:
// solve.hpp
#ifndef SOLVE_HPP
#define SOLVE_HPP
void User_matMult(float* A, float* B, float* C, int M, int K, int N, int lda, int ldb, int ldc);
#endif这只是声明了 User_matMult 函数,而它的具体实现可能是在 solve.cpp 文件中。
1.2.1多的两个函数声明与中间变量tem
但是为什么没有对应的函数的定义?
void random_matrix(int m, int n, float *C, int ldc);
void compare_matrices(int m, int n, float *a, int lda, float *b, int ldb);
float temp;
temp = A(i,j);
1.3 用GPT询问baseline里面的代码含义
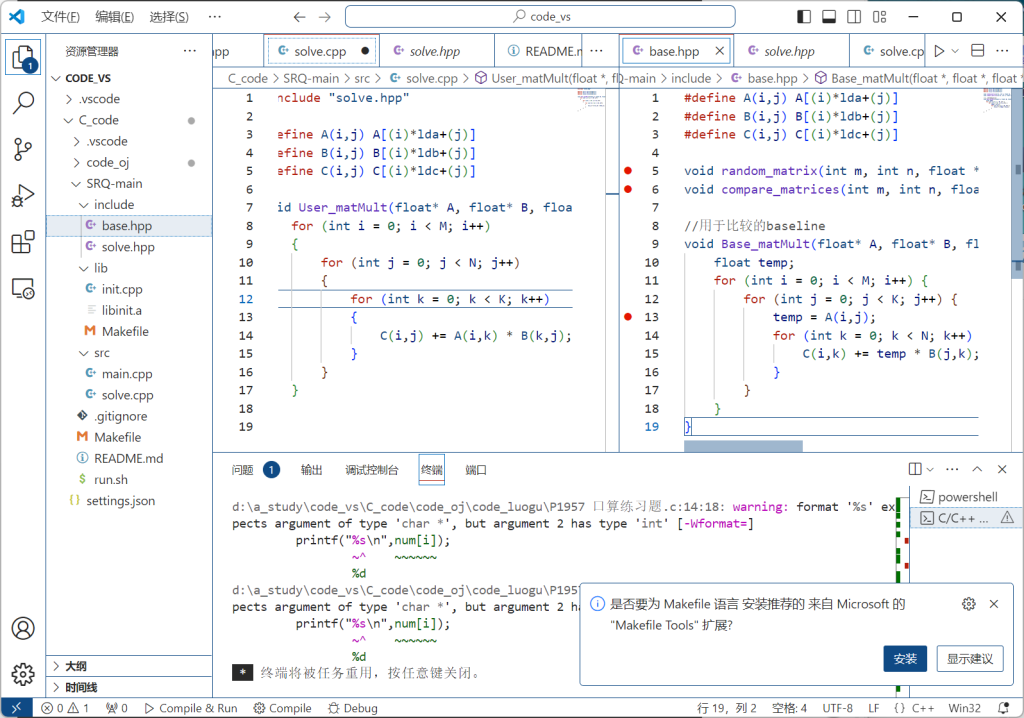
这段代码定义了一个矩阵乘法的实现,并且还使用了预处理宏来简化矩阵的索引方式。它主要包括了三个部分:宏定义、函数声明、以及矩阵乘法的实现。
代码解释
1. 宏定义部分
#define A(i,j) A[(i)*lda+(j)]
#define B(i,j) B[(i)*ldb+(j)]
#define C(i,j) C[(i)*ldc+(j)]这三行宏定义的作用是简化矩阵的索引方式。通常在矩阵运算中,二维矩阵保存在一维数组中(行优先或列优先),访问元素时需要手动计算每个元素的线性偏移。宏定义将这种繁琐的操作抽象化,使代码更易读。
A(i,j)实际上是访问矩阵A中第i行、第j列的元素,它通过表达式A[(i)*lda + (j)]计算出一维数组中对应的线性位置。lda是 leading dimension(主维度),即矩阵A的列数或步长(表示每一行在内存中的偏移量)。- 类似的,
B(i,j)和C(i,j)分别表示访问矩阵B和C中的对应位置。
2. 函数声明部分
void random_matrix(int m, int n, float *C, int ldc);
void compare_matrices(int m, int n, float *a, int lda, float *b, int ldb);random_matrix函数声明:- 用于生成一个
m x n的随机矩阵,并将结果存储在C指向的内存中,ldc是C的列步长。 compare_matrices函数声明:- 用于比较两个矩阵
a和b的元素是否一致,m和n是矩阵的行数和列数,lda和ldb分别是两个矩阵的列步长。
3. 矩阵乘法的实现 Base_matMult
void Base_matMult(float* A, float* B, float* C, int M, int K, int N, int lda, int ldb, int ldc) {
float temp;
for (int i = 0; i < M; i++) {
for (int j = 0; j < K; j++) {
temp = A(i,j);
for (int k = 0; k < N; k++) {
C(i,k) += temp * B(j,k);
}
}
}
}这个函数实现了矩阵 A 和 B 的乘法,并将结果存储在矩阵 C 中。参数解释如下:
float* A, float* B, float* C: 这三个参数分别是矩阵A、B和C的指针,用于传递矩阵的内存地址。int M, K, N: 矩阵的维度。A是M x K,B是K x N,C是M x N的矩阵。int lda, ldb, ldc: 这些参数是矩阵A、B和C的列步长(leading dimension),即它们在内存中每行的跨度。
矩阵乘法过程:
- 外层循环
for (int i = 0; i < M; i++)遍历矩阵A的行数。 - 中间循环
for (int j = 0; j < K; j++)遍历矩阵A的列数和矩阵B的行数(A和B的共同维度K)。 - 在这个循环中,
temp = A(i,j)取出A矩阵中第i行、第j列的值。 - 内层循环
for (int k = 0; k < N; k++)遍历矩阵B的列数,将A(i,j)与B(j,k)相乘,并将结果累加到C(i,k)中。
最终实现的效果是,矩阵 C 中的元素 C(i,k) 被累加了所有对应的 A(i,j) * B(j,k) 的乘积,即完成了矩阵乘法。
矩阵乘法的数学表示:
C = A * B,其中:
A是M x K矩阵B是K x N矩阵C是M x N矩阵
C(i,k) 的值是矩阵 A 的第 i 行与矩阵 B 的第 k 列相乘的结果:
[
C(i,k) = \sum_{j=0}^{K-1} A(i,j) * B(j,k)
]
总结
这段代码实现了一个常规的矩阵乘法,通过使用宏简化矩阵元素的访问,并且利用三重循环完成了 A * B = C 的计算。
1.4 omp 与 mpi以及并行化
[!note] 要点
并行就有点像多线程操作
并行化是指将一个计算任务分解为多个小任务,交给多个处理器或处理单元同时执行,从而加速任务的完成。并行计算可以显著提高大规模任务(如矩阵运算、数据处理等)的效率,尤其在科学计算、模拟和大数据处理领域具有广泛的应用。
在并行计算中,OpenMP (OMP) 和 MPI 是两种常见的并行编程模型,它们分别适用于不同类型的计算环境。
1. OpenMP (OMP)
OpenMP 是一种用于在共享内存系统中实现并行编程的编程接口。它通过简化的方式让开发者在多核 CPU 上进行并行计算。OpenMP 主要通过在代码中添加编译指令(pragma 指令)来实现多线程并行化。
OpenMP 的特点
- 共享内存:OpenMP 适用于共享内存架构,即所有线程共享同一块内存区域。
- 多线程并行:程序的某些部分可以通过指令并行执行(如
#pragma omp parallel for让循环并行运行)。 - 易于使用:OpenMP 使用编译器指令(pragma)来指示并行操作,开发者不需要管理线程的创建和销毁。
- 常用于:多核 CPU,适合那些能够在单台机器上并行执行的应用。
OpenMP 示例
#pragma omp parallel for
for (int i = 0; i < n; i++) {
// 这个循环会被多个线程并行执行
}上面的代码在循环体中插入了 #pragma omp parallel for 指令,表示该循环可以被多个线程同时执行,每个线程会处理部分循环体。
2. MPI (Message Passing Interface)
MPI 是一种用于分布式内存系统的并行编程模型,通常在多台机器(如计算集群)之间进行并行计算。它通过消息传递的方式让多个进程之间进行通信与协作。与 OpenMP 不同,MPI 适用于分布式内存架构,即每个处理器都有自己的独立内存。
MPI 的特点
- 分布式内存:MPI 适用于每个处理器或计算节点都有自己独立内存的环境,处理器之间通过网络进行通信。
- 消息传递:进程之间通过显式的消息传递进行数据交换(如发送和接收)。
- 更灵活:MPI 可以运行在不同节点之间,无需共享内存的假设。
- 常用于:高性能计算集群(如超级计算机、云计算集群),尤其适合那些需要跨多台计算机执行的大规模任务。
MPI 示例
MPI_Init(NULL, NULL); // 初始化 MPI 环境
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size); // 获取进程数
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank); // 获取当前进程 ID
// 各进程可以通过 MPI_Send 和 MPI_Recv 函数进行通信
MPI_Finalize(); // 结束 MPI 环境在 MPI 中,多个进程会同时执行同一份代码,每个进程都有一个唯一的编号(rank),用于区分它们。进程之间可以通过 MPI_Send 和 MPI_Recv 等函数交换数据。
3. 并行化的概念
并行化是通过将计算任务分解成独立的部分,交给多个计算单元(如 CPU 核心、GPU 核心、集群中的节点等)同时执行,从而减少总的执行时间。主要的目标是提高计算性能、处理大数据以及解决复杂问题。
并行化的类型
- 数据并行:数据被分成多个子集,每个子集由一个处理单元来处理。例如,一个大的数组可以分给多个线程分别计算。
- 任务并行:不同的任务或函数被分配给不同的处理单元并行执行。
- 管道并行:任务分为多个阶段,不同阶段同时在不同的处理单元上运行。
4. OpenMP 与 MPI 的对比
| 特性 | OpenMP | MPI |
|---|---|---|
| 内存模型 | 共享内存(单机多核) | 分布式内存(多机多节点) |
| 适用环境 | 多核 CPU 系统 | 高性能计算集群或多台机器 |
| 并行单元 | 线程 | 进程 |
| 通信机制 | 线程间共享内存直接访问 | 进程间通过消息传递通信 |
| 编程复杂度 | 简单,易于调试和管理 | 较复杂,需管理通信与同步 |
| 适用场景 | 单台机器上的并行计算,如图像处理、数值计算 | 大规模集群计算,如气候建模、大数据分析 |
5. 并行化的好处
- 加速计算:多个任务并行执行可以大幅缩短计算时间。
- 资源利用最大化:有效利用多核、多节点计算资源。
- 处理大规模问题:并行化能处理原本单线程无法处理的大规模问题。
总结来说,OpenMP 适用于共享内存环境(如多核 CPU),而MPI 适用于分布式内存环境(如计算集群)。两者的结合可以在不同硬件环境下实现高效的并行计算。
1.5 linux虚拟机怎么使用omp 与 mpi
[!note] 总结
omp(单机多核【多线程】)相对而言比较简单,可以直接使用。已经使用
mpi要进行相应的配置(分布式内存系统【也就是多机连用】)
Linux 虚拟机能够使用 OpenMP 和 MPI 进行并行计算。你可以在 Linux 虚拟机上配置相关的开发环境,并运行基于 OpenMP 和 MPI 的并行程序。以下是它们的基本配置和使用方法:
1. 使用 OpenMP 在 Linux 虚拟机上进行并行计算
OpenMP 安装与配置
OpenMP 是基于编译器的编程模型,大多数现代编译器(如 GCC)都支持 OpenMP。一般情况下,你不需要额外安装 OpenMP,只要使用支持 OpenMP 的编译器即可。
GCC 编译支持 OpenMP
GCC 默认支持 OpenMP,编译时只需要加上 -fopenmp 选项即可。例如:
gcc -fopenmp -o my_program my_program.c- 代码示例:
#include <omp.h>
#include <stdio.h>
int main() {
#pragma omp parallel
{
printf("Hello from thread %d\n", omp_get_thread_num());
}
return 0;
}编译并运行:
gcc -fopenmp -o hello hello.c
./helloOpenMP 常见功能
omp_set_num_threads(int):设置使用多少个线程。#pragma omp parallel:并行化区域。omp_get_thread_num():获取当前线程的 ID。
2. 使用 MPI 在 Linux 虚拟机上进行并行计算
MPI 安装与配置
MPI 在 Linux 系统上通过一些常用的 MPI 实现工具来安装,如 MPICH 和 OpenMPI。这两个库都广泛应用于高性能计算环境。
安装 OpenMPI
在 Ubuntu 或其他基于 Debian 的 Linux 发行版上,您可以通过包管理器安装 OpenMPI:
sudo apt-get update
sudo apt-get install openmpi-bin openmpi-common libopenmpi-devMPI 程序编写与运行
编写一个简单的 MPI 程序,例如:
#include <mpi.h>
#include <stdio.h>
int main(int argc, char** argv) {
MPI_Init(&argc, &argv);
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size); // 获取进程数
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank); // 获取当前进程 ID
printf("Hello from process %d out of %d processes\n", world_rank, world_size);
MPI_Finalize();
return 0;
}编译并运行:
mpicc -o mpi_hello mpi_hello.c
mpirun -np 4 ./mpi_hello这将使用 4 个进程运行该程序,每个进程会输出它的进程 ID 和总进程数。
3. 虚拟机使用 OMP 和 MPI 的要求
- 多核支持:OpenMP 依赖多核系统,因此确保虚拟机配置了多核 CPU。虚拟机管理器(如 VirtualBox 或 VMware)中可以设置虚拟机的处理器核数。
- 网络支持:MPI 在多节点通信中发挥作用时需要网络配置。如果要在不同虚拟机间运行 MPI 程序,需要配置它们的网络连接(例如同一局域网中)。但是,在单机上运行 MPI 也无需网络,只需配置好 MPI 环境。
4. 混合使用 OpenMP 和 MPI
在一些高性能计算环境中,OpenMP 和 MPI 可以混合使用:在单个节点上使用 OpenMP 来实现多线程,并在多个节点之间使用 MPI 来实现进程间通信。这种方法能够充分利用多节点集群的资源和多核处理器的性能。
结论:
- OpenMP 和 MPI 都可以在 Linux 虚拟机中运行。对于 OpenMP,只需安装 GCC 或其他支持 OpenMP 的编译器;对于 MPI,可以使用 MPICH 或 OpenMPI 这样的实现工具。
2 阅读教学文档
2.1 初略观看
- 分布优化之前的“建立”部分好像是教授性能绘图软件的配置,和优化无关,大概率可以不看
3 了解基本并行内容
3.1 MIP
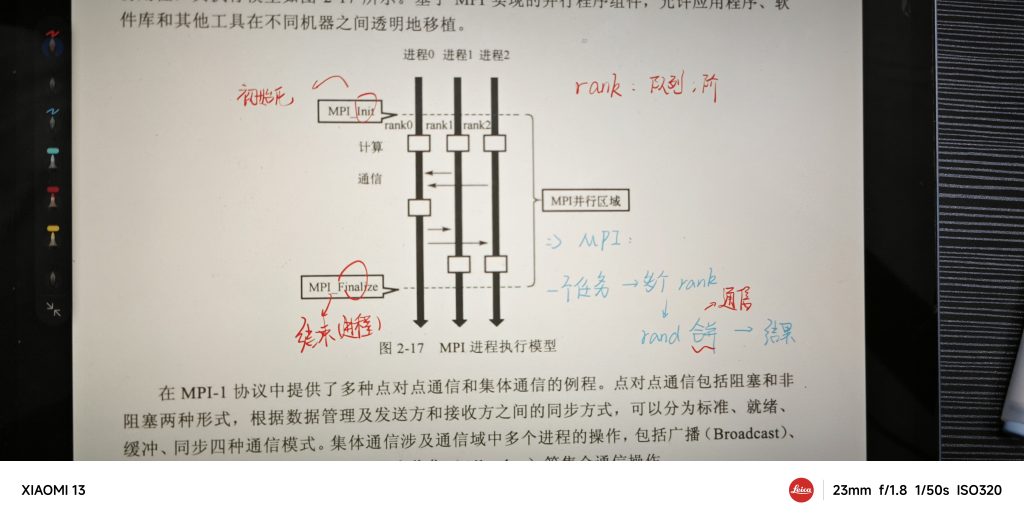
优点:
- 能够精确分配内存,最大限度发觉处理器性能(?)
- 可以多节点运行(可以集成算力?)
缺点: - 对小白很不友好,需要配置环境,还需要使用一大堆函数返回、传递信息
3.2 OMP
仅适用于公用内存的….
优点:
- 对小白非常友好,只需要引用头文件,再在需要优化的部分使用一段语句+指令限制
缺点: - 暂时没看到
4 安装open mpi
在 Linux 系统下配置 MPI(Message Passing Interface)环境,通常以 OpenMPI 或 MPICH 作为实现方式。以下是以 OpenMPI 为例的配置步骤:
1. 安装 OpenMPI
使用包管理器安装
根据你的 Linux 发行版,使用合适的包管理器安装 OpenMPI。
- Ubuntu/Debian:
sudo apt update
sudo apt install openmpi-bin openmpi-common libopenmpi-dev- CentOS/Fedora:
sudo yum install openmpi openmpi-devel使用源码编译安装
如果你需要安装特定版本的 OpenMPI,可以通过源码编译:
- 下载 OpenMPI 源码:
wget https://download.open-mpi.org/release/open-mpi/v4.1/openmpi-4.1.2.tar.gz- 解压并进入源码目录:
tar -xvf openmpi-4.1.2.tar.gz
cd openmpi-4.1.2- 配置、编译和安装:
./configure --prefix=/usr/local/openmpi
make -j4
sudo make install- 更新环境变量:
编辑~/.bashrc或~/.bash_profile文件,加入以下内容:
export PATH=/usr/local/openmpi/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/openmpi/lib:$LD_LIBRARY_PATH然后执行以下命令使修改生效:
source ~/.bashrc2. 验证 MPI 安装
安装完成后,可以通过以下命令验证 MPI 是否正确安装:
mpicc --version
mpirun --version如果这些命令输出版本信息,说明安装成功。
3. 编译 MPI 程序
使用 mpicc 编译你的 MPI 程序。例如,假设你有一个 hello_mpi.c 程序:
mpicc -o hello_mpi hello_mpi.c4. 运行 MPI 程序
使用 mpirun 或 mpiexec 运行编译好的程序。例如,使用 4 个进程运行:
mpirun -np 4 ./hello_mpi5. 配置主机文件(可选,适用于多节点运行)
如果需要在多节点上运行 MPI 程序,需要配置一个主机文件(例如 hosts 文件),包含所有节点的 IP 地址或主机名:
node1 slots=4
node2 slots=4然后通过以下命令运行:
mpirun -np 8 --hostfile hosts ./hello_mpi6. 其他
- 如果有防火墙配置,确保开放相关的端口。
- 确保各节点之间可以通过 SSH 无密码登录。
这样,你就可以在 Linux 系统上配置和运行 MPI 环境了。