24.9.29 16:00始
优化背景
1 cache缓存的硬件设计
cache(高速缓冲储存器,简称缓存)的读写比显存更快
cache的读写特点是:
- 一次读入少量多个数据
- 一次读入数据过大(循环次数过多)会造成“缓存未命中”,会再次从主存中读入包含所需变量的高速缓存块,增加运行的时间
详细补充:cache的基本知识
2 函数隐藏循环和多循环
调用函数会增加时间的开销,但是可能减少缓存未命中的问题
总结
优化大都是集中在对数据的读取问题上面
下面总结部分优化数据访问的方法:
- 循环展开
- 寄存器寄存
- 指针访问
- 调整循环顺序(贴合cache访问模式)
【思考】
为什么后面优化结果是一次循环4*4
肯定有循环展开,内存命中的问题,但联系《并行xx导论》上高速缓存的介绍,会不会与一个高速缓存通常能储存8~16倍单个内存区域的信息相关
哦,cache有大小,不一定就非是8~16
所以优化与cache无关
奇奇怪怪的一些问题
运行的时候出现报错,需要强制./gmm执行
报错内容
[root@localhost SRQ]# sh run.sh
> Job starting at: 2024-09-29 17:15:18 <
> deleting old files <
rm -f ./src/main.o ./src/solve.o gemm
> making new files <
g++ -Wall -std=c++17 -O2 -fopenmp -I./include -c src/main.cpp -o src/main.o
g++ -Wall -std=c++17 -O2 -fopenmp -I./include -c src/solve.cpp -o src/solve.o
g++ src/main.o src/solve.o -fopenmp -linit -L./lib -o gemm
> runing program <
run.sh:行25: //./gemm: 没有那个文件或目录
> Job finished at: 2024-09-29 17:15:19 <|GPT解释
从您提供的输出信息来看,出现了错误信息:
run.sh:行25: //./gemm: 没有那个文件或目录这表明在执行 ./gemm 时,系统找不到该文件。这个问题通常有以下几种可能的原因和解决方案:
1. 确保生成可执行文件
在运行 run.sh 脚本的过程中,您应该检查在最后一步是否成功生成了 gemm 可执行文件。可以手动运行 g++ 命令来查看是否有错误:
g++ src/main.o src/solve.o -fopenmp -linit -L./lib -o gemm2. 检查文件路径
确认 gemm 是否位于脚本的当前工作目录中。在终端中运行以下命令,检查是否存在 gemm 文件:
ls -l ./gemm如果文件不存在,请检查编译过程是否成功生成了 gemm。如果 gemm 文件确实生成,但不在预期目录中,请查看生成文件的路径。
3. 检查脚本内容
请检查 run.sh 脚本的内容,确保在正确的目录中调用了 ./gemm。在脚本中,确保 ./gemm 的路径是正确的,且没有多余的字符或错误的路径。
4. 编译错误
如果在编译过程中出现了错误,可能会导致可执行文件没有被创建。查看编译时的输出信息,确保没有错误。编译错误通常会显示在您的终端上。
5. 权限问题
如果 gemm 文件已经生成,但没有执行权限,您可以使用以下命令添加执行权限:
chmod +x ./gemm6. 修复 run.sh 脚本
确保在 run.sh 脚本中,您正在正确调用可执行文件。可以在调用 ./gemm 之前添加一些检查代码,比如:
if [ ! -f ./gemm ]; then
echo "Error: gemm executable not found!"
exit 1
fi
./gemm 1024这将帮助您更好地调试问题,并提供更明确的错误信息。
总结
请按照上述步骤逐一检查,确保在执行 run.sh 时,能够成功生成 gemm 可执行文件,并且能够在正确的路径下找到它。如果还有其他问题,请随时提供更多信息。
Optimization1 优化 1
MMult0.c代码
【总结】
初始的矩阵计算代码
/* Create macros so that the matrices are stored in column-major order */
#define A(i,j) a[ (j)*lda + (i) ]
#define B(i,j) b[ (j)*ldb + (i) ]
#define C(i,j) c[ (j)*ldc + (i) ]
/* Routine for computing C = A * B + C */
void MY_MMult( int m, int n, int k,
double *a, int lda, double *b,
int ldb, double *c, int ldc )
{
int i, j, p;
for ( i=0; i<m; i++ )
{ /* Loop over the rows of C */
for ( j=0; j<n; j++ )
{ /* Loop over the columns of C */
for ( p=0; p<k; p++ )
{ /* Update C( i,j ) with the inner product of the ith row of A and the jth column of B */
C( i,j ) = C( i,j ) + A( i,p ) * B( p,j );
}
}
}
} MMult1.c代码
【注意!!】
不能直接copy github上面的优化代码,然后替代solve上面的代码(因为这个项目里的其它的文件有一些特定的东西(比如说变量定义),copy过来的代码会出现不匹配的问题
解决方法:自己修改,匹配类型
【释义】
“在子例程中隐藏计算”
GPT解释:
内部循环被封装在一个名为AddDot的子例程(或函数)中。换句话说,循环的实现细节被隐藏在这个函数里,使用时只需调用这个函数,而不需要关心其具体的实现。这是一种提高代码可读性和复用性的做法。
PS:这里已经打开了一层循环
/* Create macros so that the matrices are stored in column-major order */
#define A(i,j) a[ (j)*lda + (i) ]
#define B(i,j) b[ (j)*ldb + (i) ]
#define C(i,j) c[ (j)*ldc + (i) ]
/* Routine for computing C = A * B + C */
void AddDot( int, double *, int, double *, double * );
void MY_MMult( int m, int n, int k, double *a, int lda,
double *b, int ldb,
double *c, int ldc )
{
int i, j;
for ( j=0; j<n; j+=1 ){ /* Loop over the columns of C */
for ( i=0; i<m; i+=1 ){ /* Loop over the rows of C */
/* Update the C( i,j ) with the inner product of the ith row of A
and the jth column of B */
AddDot( k, &A( i,0 ), lda, &B( 0,j ), &C( i,j ) );
}
}
}
/* Create macro to let X( i ) equal the ith element of x */
#define X(i) x[ (i)*incx ]
void AddDot( int k, double *x, int incx, double *y, double *gamma )
{
/* compute gamma := x' * y + gamma with vectors x and y of length n.
Here x starts at location x with increment (stride) incx and y starts at location y and has (implicit) stride of 1.
*/
int p;
for ( p=0; p<k; p++ ){
*gamma += X( p ) * y[ p ];
}
}主要区别
#define X(i) x[ (i)*incx ]
void AddDot( int k, double *x, int incx, double *y, double *gamma )
{
/* compute gamma := x' * y + gamma with vectors x and y of length n.
Here x starts at location x with increment (stride) incx and y starts at location y and has (implicit) stride of 1.
*/
int p;
for ( p=0; p<k; p++ ){
*gamma += X( p ) * y[ p ];
}
}多了一个
AddDot用来计算新矩阵内的元素
目前内容其实和solvo.cpp中的C(i,j) += A(i,k) * B(k,j);是一样的
MMult1.c修改出现的问题
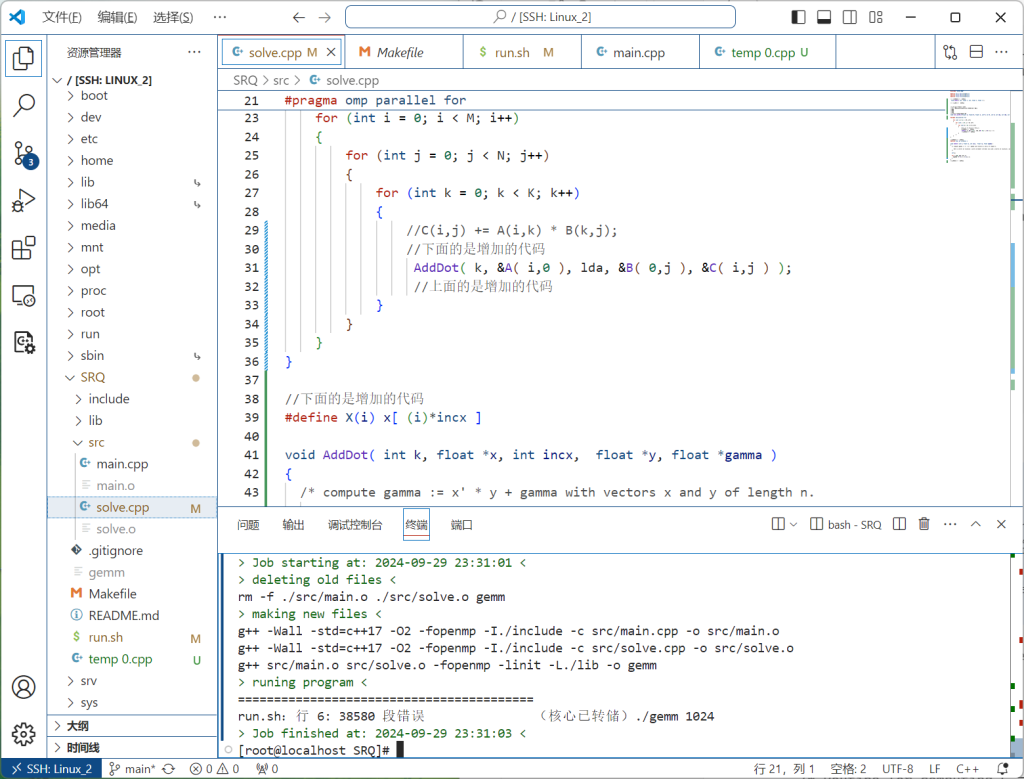
报错执行 ./gemm 1024 时,发生了段错误(Segmentation Fault),即程序试图访问一个不合法的内存区域,导致崩溃。具体原因可能有很多,包括非法指针访问、数组越界、动态内存分配失败等
于是我注释掉omp并行后
【解释】
为什么删除#pragma omp parallel for?使用
#pragma omp parallel for时,可能出现访问越界的错误,通常是因为多个线程同时访问或修改同一个数组或数据结构,导致竞争条件。这种情况下,某些线程可能会超出数组的边界,尤其是在没有正确划分任务或保护共享资源的情况下。确保每个线程操作不同的数据段,或者使用适当的同步机制,可以帮助避免此类错误。
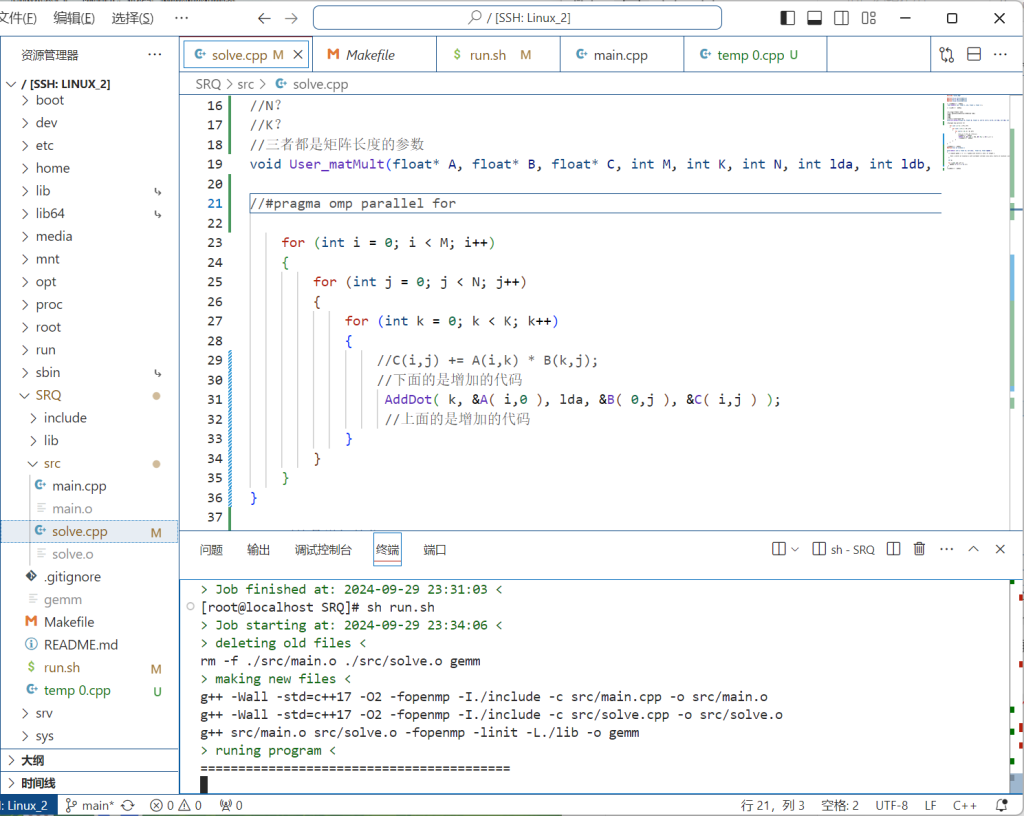
出现不反馈优化时间的问题
思考:由优化一出现的问题产生的思考
#pragma omp parallel for是否会导致越界问题?
你理解得很对。单单添加 #pragma omp parallel for 并不会直接导致越界问题。越界问题通常是由代码中的逻辑错误(例如,循环边界条件设置不当)引起的,而不是 OpenMP 本身的问题。
具体说明:
- 越界访问的根本原因:越界问题本质上是由代码中错误的数组访问引起的,比如在原始的循环里,条件写成
i <= N(而不是i < N),这导致访问a[N],超出了数组的合法索引范围。如果你不并行化这个循环,这个问题依然存在,只不过在单线程模式下,可能未必立即显现出来,比如有些编译器可能会忽略或延迟这种错误。 - 并行化的影响:使用
#pragma omp parallel for后,多个线程会同时运行循环的不同部分,如果某个线程碰巧执行到那个导致越界访问的部分,可能会更容易引发程序崩溃或报错。并行化让问题更容易显现,但它并不是问题的根本原因。
添加 OpenMP 并行化后的潜在问题:
并行化本身不会引入越界问题,但如果代码中原本有错误(如越界访问、数据竞争),并行化会放大这些问题,常见的错误可能有:
- 循环的错误边界:像前面的例子那样,如果循环写成
i <= N,那么并行化后可能多个线程会尝试同时访问越界的内存位置,导致程序崩溃。 - 共享数据的竞争条件:如果不同线程同时访问或修改共享数据,可能会产生不可预期的行为。例如,如果某个数组没有按照不同线程的索引进行分配(比如多个线程同时修改同一个数组位置),则会出现数据竞争。
结论:
#pragma omp parallel for只是让循环并行化,增加了程序执行的并发性,它本身不会引入越界问题。- 越界访问问题是由于代码中的逻辑错误,并行化可能会让这个问题更加明显或频繁。
- 编写并行程序时,要特别注意边界条件、任务划分和线程间的同步问题。
Optimization2 优化 2
源码
/* Create macros so that the matrices are stored in column-major order */
#define A(i,j) a[ (j)*lda + (i) ]
#define B(i,j) b[ (j)*ldb + (i) ]
#define C(i,j) c[ (j)*ldc + (i) ]
/* Routine for computing C = A * B + C */
void AddDot( int, double *, int, double *, double * );
void MY_MMult( int m, int n, int k, double *a, int lda,
double *b, int ldb,
double *c, int ldc )
{
int i, j;
for ( j=0; j<n; j+=4 ){ /* Loop over the columns of C, unrolled by 4 */
for ( i=0; i<m; i+=1 ){ /* Loop over the rows of C */
/* Update the C( i,j ) with the inner product of the ith row of A
and the jth column of B */
AddDot( k, &A( i,0 ), lda, &B( 0,j ), &C( i,j ) );
/* Update the C( i,j+1 ) with the inner product of the ith row of A
and the (j+1)th column of B */
AddDot( k, &A( i,0 ), lda, &B( 0,j+1 ), &C( i,j+1 ) );
/* Update the C( i,j+2 ) with the inner product of the ith row of A
and the (j+2)th column of B */
AddDot( k, &A( i,0 ), lda, &B( 0,j+2 ), &C( i,j+2 ) );
/* Update the C( i,j+3 ) with the inner product of the ith row of A
and the (j+1)th column of B */
AddDot( k, &A( i,0 ), lda, &B( 0,j+3 ), &C( i,j+3 ) );
//内部循环展开,所以外部一次循环后j += 4
}
}
}
//降低循环次数,一次循环进行四次计算
/* Create macro to let X( i ) equal the ith element of x */
#define X(i) x[ (i)*incx ]
void AddDot( int k, double *x, int incx, double *y, double *gamma )
{
/* compute gamma := x' * y + gamma with vectors x and y of length n.
Here x starts at location x with increment (stride) incx and y starts at location y and has (implicit) stride of 1.
*/
int p;
for ( p=0; p<k; p++ ){
*gamma += X( p ) * y[ p ];
}
}[!note] 区别:
引用了四次AddDot
并且第一个for循环后有一个j+=4,降低循环次数GPT解释(与优化1相比)
这两个代码的核心区别在于 第一个代码使用了循环展开技术,而第二个代码没有。具体来说,它们在矩阵乘法的计算方式和性能优化上有所不同。
主要区别:
- 循环展开 (Loop Unrolling):
- 第一个代码:
- 通过
j+=4的方式每次处理矩阵 C 的 4 列。它在内循环中使用了 4 次AddDot,分别计算矩阵 C 的第i行与矩阵 B 的第j、j+1、j+2和j+3列的乘积。 - 这种循环展开的方式有助于提高性能,因为它减少了循环控制的开销,并增加了数据的缓存命中率。
- 通过
- 第二个代码:
- 没有循环展开。通过
j+=1的方式逐列处理矩阵 C。每次内循环只计算矩阵 C 的第i行和矩阵 B 的第j列的乘积。 - 这种逐列处理的方法较为直观,但没有特别针对性能进行优化。
- 没有循环展开。通过
- 性能优化:
- 第一个代码:由于每次处理 4 列,可以更好地利用现代处理器的缓存和流水线机制。矩阵 B 的多个列数据可以一次性加载到缓存中,从而减少内存访问的次数,增加数据局部性和处理效率。这种方式在处理较大矩阵时通常会有更好的性能表现。
- 第二个代码:每次只处理矩阵 C 的一列,虽然实现简单,但每次内循环结束后,处理器可能需要重新加载矩阵 B 的数据,导致更多的内存访问,缓存利用率较低。对于大型矩阵乘法,这种方式的性能较低。
- 复杂性:
- 第一个代码:增加了实现的复杂性。循环展开使得代码结构更加复杂,并且需要额外的
AddDot调用来处理多个列的乘积。虽然这提升了性能,但也使得代码可读性变差。 - 第二个代码:实现更加简洁,每列处理一次,不需要考虑循环展开,代码更加易读和维护。
总结:
- 第一个代码 通过循环展开技术和处理 4 列数据的方式提升了性能,特别适合大规模矩阵运算。它的优势在于减少了循环控制和内存访问的开销。
- 第二个代码 实现简单,但没有进行性能优化,适合理解矩阵乘法的基本原理,但在处理大规模矩阵时性能不如第一个代码。
因此,第一个代码在性能上优于第二个代码,尤其是在大规模矩阵运算的情况下。
所以:
> 在子进程中隐藏计算
Optimization3 优化 3
[!note] 总结
通过循环展开来进行优化
(但循环都展开了,那omp的for循环优化还存在吗?
外层的肯定还存在哦
思路:将四次计算用一个函数AddDot给容纳起来,然后一次引用就行
专业语言:在子例程 AddDot1x4 中一次计算 C 四个元素,该子例程一次执行四个内部乘积
(为什么这么做?)
应该是增加缓存的命中率【见书上的解释】
源码:
/* Create macros so that the matrices are stored in column-major order */
#define A(i,j) a[ (j)*lda + (i) ]
#define B(i,j) b[ (j)*ldb + (i) ]
#define C(i,j) c[ (j)*ldc + (i) ]
/* Routine for computing C = A * B + C */
void AddDot( int, double *, int, double *, double * );
void AddDot1x4( int, double *, int, double *, int, double *, int )
void MY_MMult( int m, int n, int k, double *a, int lda,
double *b, int ldb,
double *c, int ldc )
{
int i, j;
for ( j=0; j<n; j+=4 ){ /* Loop over the columns of C, unrolled by 4 */
for ( i=0; i<m; i+=1 ){ /* Loop over the rows of C */
/* Update C( i,j ), C( i,j+1 ), C( i,j+2 ), and C( i,j+3 ) in
one routine (four inner products) */
AddDot1x4( k, &A( i,0 ), lda, &B( 0,j ), ldb, &C( i,j ), ldc );
}
}
}
void AddDot1x4( int k, double *a, int lda, double *b, int ldb, double *c, int ldc )
{
/* So, this routine computes four elements of C:
C( 0, 0 ), C( 0, 1 ), C( 0, 2 ), C( 0, 3 ).
Notice that this routine is called with c = C( i, j ) in the
previous routine, so these are actually the elements
C( i, j ), C( i, j+1 ), C( i, j+2 ), C( i, j+3 )
in the original matrix C */
AddDot( k, &A( 0, 0 ), lda, &B( 0, 0 ), &C( 0, 0 ) );
AddDot( k, &A( 0, 0 ), lda, &B( 0, 1 ), &C( 0, 1 ) );
AddDot( k, &A( 0, 0 ), lda, &B( 0, 2 ), &C( 0, 2 ) );
AddDot( k, &A( 0, 0 ), lda, &B( 0, 3 ), &C( 0, 3 ) );
}
/* Create macro to let X( i ) equal the ith element of x */
#define X(i) x[ (i)*incx ]
void AddDot( int k, double *x, int incx, double *y, double *gamma )
{
/* compute gamma := x' * y + gamma with vectors x and y of length n.
Here x starts at location x with increment (stride) incx and y starts at location y and has (implicit) stride of 1.
*/
int p;
for ( p=0; p<k; p++ ){
*gamma += X( p ) * y[ p ];
}
}以上代码实现了循环展开的优化
循环展开:将多次循环拆开为一次函数的引用
[!note] 问题:为什么循环展开后就可以进行下面的优化?
- 循环展开(Loop Unrolling):这是编译优化的一种技术,通过减少循环的控制开销(如分支预测和跳转)以及增加流水线并行度来提高性能。由于矩阵乘法是典型的计算密集型任务,展开循环可以让处理器更高效地使用其计算资源。·
- 内存访问模式:一次性计算和更新 4 列
C可以减少访问内存的次数,同时提高缓存的利用率。当矩阵数据按行或按块在缓存中时,这种方式可以让数据加载效率更高,减少缓存未命中的概率。- 减少函数调用次数:由于
AddDot函数用于计算和更新单个元素的矩阵乘积(内积),通过在循环中展开,实际上减少了函数调用的次数,使得每次调用AddDot都能为不同的列更新C,提高效率。
Optimization4 优化 4(这个好像是之前的优化版本)
[!note] 总结
【确实还是没有看懂,啊哈哈哈】
- 循环展开
打开两次循环
- 块矩阵运算
一次计算4*4
[!note] 问题 1
为什么循环展开(loop unrolling) 和 块矩阵运算(block matrix multiplication)能提高运算性能?
[!note] 问题 2
为什么是变为4*4?
那运行的矩阵也必须要4n*4n吗?
/* Create macros so that the matrices are stored in column-major order */
#define A(i,j) a[ (j)*lda + (i) ]
#define B(i,j) b[ (j)*ldb + (i) ]
#define C(i,j) c[ (j)*ldc + (i) ]
/* Routine for computing C = A * B + C */
void AddDot4x4( int, double *, int, double *, int, double *, int );
void AddDot( int, double *, int, double *, double * );
void MY_MMult( int m, int n, int k, double *a, int lda,
double *b, int ldb,
double *c, int ldc )
{
int i, j;
for ( j=0; j<n; j+=4 ){ /* Loop over the columns of C, unrolled by 4 */
for ( i=0; i<m; i+=4 ){ /* Loop over the rows of C */
/* Update C( i,j ), C( i,j+1 ), C( i,j+2 ), and C( i,j+3 ) in
one routine (four inner products) */
AddDot4x4( k, &A( i,0 ), lda, &B( 0,j ), ldb, &C( i,j ), ldc );
}
}
}
void AddDot4x4( int k, double *a, int lda, double *b, int ldb, double *c, int ldc )
{
/* So, this routine computes a 4x4 block of matrix A
C( 0, 0 ), C( 0, 1 ), C( 0, 2 ), C( 0, 3 ).
C( 1, 0 ), C( 1, 1 ), C( 1, 2 ), C( 1, 3 ).
C( 2, 0 ), C( 2, 1 ), C( 2, 2 ), C( 2, 3 ).
C( 3, 0 ), C( 3, 1 ), C( 3, 2 ), C( 3, 3 ).
Notice that this routine is called with c = C( i, j ) in the
previous routine, so these are actually the elements
C( i , j ), C( i , j+1 ), C( i , j+2 ), C( i , j+3 )
C( i+1, j ), C( i+1, j+1 ), C( i+1, j+2 ), C( i+1, j+3 )
C( i+2, j ), C( i+2, j+1 ), C( i+2, j+2 ), C( i+2, j+3 )
C( i+3, j ), C( i+3, j+1 ), C( i+3, j+2 ), C( i+3, j+3 )
in the original matrix C
In this version, we "inline" AddDot */
int p;
/* First row */
// AddDot( k, &A( 0, 0 ), lda, &B( 0, 0 ), &C( 0, 0 ) );
for ( p=0; p<k; p++ ){
C( 0, 0 ) += A( 0, p ) * B( p, 0 );
}
// AddDot( k, &A( 0, 0 ), lda, &B( 0, 1 ), &C( 0, 1 ) );
for ( p=0; p<k; p++ ){
C( 0, 1 ) += A( 0, p ) * B( p, 1 );
}
// AddDot( k, &A( 0, 0 ), lda, &B( 0, 2 ), &C( 0, 2 ) );
for ( p=0; p<k; p++ ){
C( 0, 2 ) += A( 0, p ) * B( p, 2 );
}
// AddDot( k, &A( 0, 0 ), lda, &B( 0, 3 ), &C( 0, 3 ) );
for ( p=0; p<k; p++ ){
C( 0, 3 ) += A( 0, p ) * B( p, 3 );
}
/* Second row */
// AddDot( k, &A( 1, 0 ), lda, &B( 0, 0 ), &C( 1, 0 ) );
for ( p=0; p<k; p++ ){
C( 1, 0 ) += A( 1, p ) * B( p, 0 );
}
// AddDot( k, &A( 1, 0 ), lda, &B( 0, 1 ), &C( 1, 1 ) );
for ( p=0; p<k; p++ ){
C( 1, 1 ) += A( 1, p ) * B( p, 1 );
}
// AddDot( k, &A( 1, 0 ), lda, &B( 0, 2 ), &C( 1, 2 ) );
for ( p=0; p<k; p++ ){
C( 1, 2 ) += A( 1, p ) * B( p, 2 );
}
// AddDot( k, &A( 1, 0 ), lda, &B( 0, 3 ), &C( 1, 3 ) );
for ( p=0; p<k; p++ ){
C( 1, 3 ) += A( 1, p ) * B( p, 3 );
}
/* Third row */
// AddDot( k, &A( 2, 0 ), lda, &B( 0, 0 ), &C( 2, 0 ) );
for ( p=0; p<k; p++ ){
C( 2, 0 ) += A( 2, p ) * B( p, 0 );
}
// AddDot( k, &A( 2, 0 ), lda, &B( 0, 1 ), &C( 2, 1 ) );
for ( p=0; p<k; p++ ){
C( 2, 1 ) += A( 2, p ) * B( p, 1 );
}
// AddDot( k, &A( 2, 0 ), lda, &B( 0, 2 ), &C( 2, 2 ) );
for ( p=0; p<k; p++ ){
C( 2, 2 ) += A( 2, p ) * B( p, 2 );
}
// AddDot( k, &A( 2, 0 ), lda, &B( 0, 3 ), &C( 2, 3 ) );
for ( p=0; p<k; p++ ){
C( 2, 3 ) += A( 2, p ) * B( p, 3 );
}
/* Four row */
// AddDot( k, &A( 3, 0 ), lda, &B( 0, 0 ), &C( 3, 0 ) );
for ( p=0; p<k; p++ ){
C( 3, 0 ) += A( 3, p ) * B( p, 0 );
}
// AddDot( k, &A( 3, 0 ), lda, &B( 0, 1 ), &C( 3, 1 ) );
for ( p=0; p<k; p++ ){
C( 3, 1 ) += A( 3, p ) * B( p, 1 );
}
// AddDot( k, &A( 3, 0 ), lda, &B( 0, 2 ), &C( 3, 2 ) );
for ( p=0; p<k; p++ ){
C( 3, 2 ) += A( 3, p ) * B( p, 2 );
}
// AddDot( k, &A( 3, 0 ), lda, &B( 0, 3 ), &C( 3, 3 ) );
for ( p=0; p<k; p++ ){
C( 3, 3 ) += A( 3, p ) * B( p, 3 );
}
}解——问题1
通过这种方式(即 循环展开(loop unrolling) 和 块矩阵运算(block matrix multiplication)),矩阵乘法可以更好地利用处理器的缓存和并行计算资源,进而提高性能,特别是在大规模矩阵运算中,原因如下:
1. 提高缓存的利用率
处理器的缓存用于加速数据访问,而在矩阵乘法中,如果数据可以重复使用而不需要频繁从主存加载,就能显著提高效率。以下是块矩阵运算如何优化缓存利用的原因:
- 数据局部性(Data Locality):将矩阵划分为较小的块(例如 4×4 块),这样可以确保一个块的元素在处理时保持在缓存中,减少缓存未命中的情况。块的大小通常是根据缓存容量来设计的,以最大化缓存效率。这样,处理一个小块时,所有需要的数据都可以在缓存中被频繁访问,而不需要重复从主存加载。
- 减少缓存未命中(Cache Misses):在大规模矩阵运算中,直接对全局矩阵进行操作可能会因为数据太大,频繁发生缓存未命中,导致访问主存的延迟。如果将矩阵分块操作,则可以将这些小块放入缓存,从而提高缓存命中率。
附:
减少因为未命中而读取主存中包含所需信息的整个高速缓存块的时间
(见红框下方文字说明)

例子:在上面的代码中,4×4 块的 C 中数据的更新只会访问矩阵 A 的几行和矩阵 B 的几列。由于这些行和列很小,能很好地存放在缓存中,避免频繁的主存访问。
2. 减少循环控制开销
循环展开的好处之一是减少了每次迭代中的循环控制开销,包括循环的计数、跳转和条件检查。
- 减少分支预测错误:现代处理器通过分支预测来减少跳转和条件判断的开销。每次循环迭代都需要分支跳转,可能带来性能损失。通过展开循环,程序可以一次性完成更多的计算,从而减少循环计数器和条件检查的开销。
- 流水线效率(Pipeline Efficiency):循环展开可以帮助处理器的指令流水线更好地运行。处理器的流水线是并行处理指令的一种架构,通过循环展开可以减少处理器等待分支预测和跳转操作的时间,使得更多的指令能够顺序执行,提高流水线效率。
例子:在 AddDot4x4 的例子中,外部循环每次迭代会同时处理 4 列和 4 行的数据,减少了处理一个元素后进行循环跳转的次数。
3. 并行计算与向量化(SIMD 指令)
现代处理器支持 SIMD(Single Instruction, Multiple Data) 指令集,这类指令允许处理器在单个时钟周期内对多个数据进行相同的操作。
- 向量化运算:通过循环展开,代码能够更好地与处理器的 SIMD 指令集结合。例如,在处理4个元素时,可以使用一个 SIMD 指令同时更新4个矩阵元素,这比逐个元素处理更高效。SIMD 能够在每个时钟周期中并行处理多个数值,这对于线性代数运算来说是一个巨大的加速。
例子:在 4×4 块的矩阵乘法中,处理器可以通过 SIMD 指令同时处理 4 个矩阵元素的乘法和累加,减少指令数量,提高并行度。
4. 减少内存带宽瓶颈
矩阵乘法是典型的计算和内存密集型任务,处理器的性能在很大程度上受限于内存带宽。通过块矩阵的方式,尽可能多地将数据保留在缓存中,减少对内存的频繁访问,从而缓解内存带宽瓶颈问题。
例子:在 AddDot4x4 中,4×4 块的矩阵数据在缓存中处理时,减少了频繁访问内存的次数,也避免了缓存溢出问题(当数据太多时,缓存中的数据会被替换)。
5. 提高并行性(Thread-level Parallelism, TLP)
通过将矩阵分块,可以将这些块分配给多个线程并行处理。每个线程可以独立地计算一个或多个块,这样多个处理器核心可以同时工作,加快矩阵乘法的整体速度。
- 多线程处理(OpenMP 等):将矩阵乘法任务分割成多个子任务,通过并行化来加速。例如,使用
#pragma omp parallel for结合块矩阵乘法,多个线程可以同时处理不同的 4×4 块,大幅提高计算效率。
6. 减少内存访问冲突
在大规模矩阵乘法中,不同的线程可能同时访问相同的内存区域,导致内存访问冲突(Memory Access Conflict)。通过分块的方式,保证每个线程处理独立的块,可以避免这些冲突,提升并行计算的效率。
总结
通过 块矩阵乘法 和 循环展开,矩阵乘法可以:
- 提升缓存利用率,减少缓存未命中。
- 减少循环控制开销,提高流水线效率。
- 利用向量化和并行计算,通过 SIMD 指令和多线程技术加速计算。
- 缓解内存带宽瓶颈,减少对内存的频繁访问。
这些优化技术在大规模矩阵乘法中尤其显著,因为矩阵越大,数据的访问和计算越频繁,这些技术可以极大地减少内存访问时间和处理器的闲置时间,从而显著提高性能。
Optimization4 优化 4
[!note] 总结
把原来的AddDot函数拆开成循环,加入AddDot1x4函数中,组成一个一次计算四次内积的函数
源码:
/* Create macros so that the matrices are stored in column-major order */
#define A(i,j) a[ (j)*lda + (i) ]
#define B(i,j) b[ (j)*ldb + (i) ]
#define C(i,j) c[ (j)*ldc + (i) ]
/* Routine for computing C = A * B + C */
void AddDot1x4( int, double *, int, double *, int, double *, int )
void MY_MMult( int m, int n, int k, double *a, int lda,
double *b, int ldb,
double *c, int ldc )
{
int i, j;
for ( j=0; j<n; j+=4 ){ /* Loop over the columns of C, unrolled by 4 */
for ( i=0; i<m; i+=1 ){ /* Loop over the rows of C */
/* Update C( i,j ), C( i,j+1 ), C( i,j+2 ), and C( i,j+3 ) in
one routine (four inner products) */
AddDot1x4( k, &A( i,0 ), lda, &B( 0,j ), ldb, &C( i,j ), ldc );
}
}
}
void AddDot1x4( int k, double *a, int lda, double *b, int ldb, double *c, int ldc )
{
/* So, this routine computes four elements of C:
C( 0, 0 ), C( 0, 1 ), C( 0, 2 ), C( 0, 3 ).
Notice that this routine is called with c = C( i, j ) in the
previous routine, so these are actually the elements
C( i, j ), C( i, j+1 ), C( i, j+2 ), C( i, j+3 )
in the original matrix C.
In this version, we "inline" AddDot */
int p;
// AddDot( k, &A( 0, 0 ), lda, &B( 0, 0 ), &C( 0, 0 ) );
for ( p=0; p<k; p++ ){
C( 0, 0 ) += A( 0, p ) * B( p, 0 );
}
// AddDot( k, &A( 0, 0 ), lda, &B( 0, 1 ), &C( 0, 1 ) );
for ( p=0; p<k; p++ ){
C( 0, 1 ) += A( 0, p ) * B( p, 1 );
}
// AddDot( k, &A( 0, 0 ), lda, &B( 0, 2 ), &C( 0, 2 ) );
for ( p=0; p<k; p++ ){
C( 0, 2 ) += A( 0, p ) * B( p, 2 );
}
// AddDot( k, &A( 0, 0 ), lda, &B( 0, 3 ), &C( 0, 3 ) );
for ( p=0; p<k; p++ ){
C( 0, 3 ) += A( 0, p ) * B( p, 3 );
}
}Optimization5 优化 5
[!note] 总结
将原来的一次计算四次循环/计算4次内积
变成一次一循环,一循环计算四次内积循环展开,降低循环时间开销
贴合cacahe一次读入少量多个数据的特点
/* Create macros so that the matrices are stored in column-major order */
#define A(i,j) a[ (j)*lda + (i) ]
#define B(i,j) b[ (j)*ldb + (i) ]
#define C(i,j) c[ (j)*ldc + (i) ]
/* Routine for computing C = A * B + C */
void AddDot1x4( int, double *, int, double *, int, double *, int );
void MY_MMult( int m, int n, int k, double *a, int lda,
double *b, int ldb,
double *c, int ldc )
{
int i, j;
for ( j=0; j<n; j+=4 ){ /* Loop over the columns of C, unrolled by 4 */
for ( i=0; i<m; i+=1 ){ /* Loop over the rows of C */
/* Update C( i,j ), C( i,j+1 ), C( i,j+2 ), and C( i,j+3 ) in
one routine (four inner products) */
AddDot1x4( k, &A( i,0 ), lda, &B( 0,j ), ldb, &C( i,j ), ldc );
}
}
}
void AddDot1x4( int k, double *a, int lda, double *b, int ldb, double *c, int ldc )
{
/* So, this routine computes four elements of C:
C( 0, 0 ), C( 0, 1 ), C( 0, 2 ), C( 0, 3 ).
Notice that this routine is called with c = C( i, j ) in the
previous routine, so these are actually the elements
C( i, j ), C( i, j+1 ), C( i, j+2 ), C( i, j+3 )
in the original matrix C.
In this version, we merge the four loops, computing four inner
products simultaneously. */
int p;
// AddDot( k, &A( 0, 0 ), lda, &B( 0, 0 ), &C( 0, 0 ) );
// AddDot( k, &A( 0, 0 ), lda, &B( 0, 1 ), &C( 0, 1 ) );
// AddDot( k, &A( 0, 0 ), lda, &B( 0, 2 ), &C( 0, 2 ) );
// AddDot( k, &A( 0, 0 ), lda, &B( 0, 3 ), &C( 0, 3 ) );
for ( p=0; p<k; p++ ){
C( 0, 0 ) += A( 0, p ) * B( p, 0 );
C( 0, 1 ) += A( 0, p ) * B( p, 1 );
C( 0, 2 ) += A( 0, p ) * B( p, 2 );
C( 0, 3 ) += A( 0, p ) * B( p, 3 );
}
}Optimization6 优化 6
[!note] 总结
使用寄存器对临时数据进行储存
寄存器(只)储存了A矩阵中的数据,然后用寄存器分别储存内积结果,最后转化为目标矩阵的值
寄存器降低了内存访问的次数,提高了数据访问的速度
不明白AddDot1x4函数内部的具体计算
源码:
/* Create macros so that the matrices are stored in column-major order */
#define A(i,j) a[ (j)*lda + (i) ]
#define B(i,j) b[ (j)*ldb + (i) ]
#define C(i,j) c[ (j)*ldc + (i) ]
/* Routine for computing C = A * B + C */
void AddDot1x4( int, double *, int, double *, int, double *, int )
void MY_MMult( int m, int n, int k, double *a, int lda,
double *b, int ldb,
double *c, int ldc )
{
int i, j;
for ( j=0; j<n; j+=4 ){ /* Loop over the columns of C, unrolled by 4 */
for ( i=0; i<m; i+=1 ){ /* Loop over the rows of C */
/* Update C( i,j ), C( i,j+1 ), C( i,j+2 ), and C( i,j+3 ) in
one routine (four inner products) */
AddDot1x4( k, &A( i,0 ), lda, &B( 0,j ), ldb, &C( i,j ), ldc );
}
}
}
void AddDot1x4( int k, double *a, int lda, double *b, int ldb, double *c, int ldc )
{
/* So, this routine computes four elements of C:
C( 0, 0 ), C( 0, 1 ), C( 0, 2 ), C( 0, 3 ).
Notice that this routine is called with c = C( i, j ) in the
previous routine, so these are actually the elements
C( i, j ), C( i, j+1 ), C( i, j+2 ), C( i, j+3 )
in the original matrix C.
In this version, we accumulate in registers and put A( 0, p ) in a register */
int p;
register double
/* hold contributions to
C( 0, 0 ), C( 0, 1 ), C( 0, 2 ), C( 0, 3 ) */
c_00_reg, c_01_reg, c_02_reg, c_03_reg,
/* holds A( 0, p ) */
a_0p_reg;
c_00_reg = 0.0;
c_01_reg = 0.0;
c_02_reg = 0.0;
c_03_reg = 0.0;
for ( p=0; p<k; p++ ){
a_0p_reg = A( 0, p );
c_00_reg += a_0p_reg * B( p, 0 );
c_01_reg += a_0p_reg * B( p, 1 );
c_02_reg += a_0p_reg * B( p, 2 );
c_03_reg += a_0p_reg * B( p, 3 );
}
C( 0, 0 ) += c_00_reg;
C( 0, 1 ) += c_01_reg;
C( 0, 2 ) += c_02_reg;
C( 0, 3 ) += c_03_reg;
}Optimization7 优化 7
[!note] 总结
用指针去访问B数组
思考:为什么不直接用寄存器储存B数组的值,然后进行计算?
也许这样寄存器储存的数值太多了,会出现问题
用指针访问,加快了数据访问的速度附加:
- 使用指针访问B数组可以提高内存访问效率,尤其是在处理连续内存位置时,能减少计算地址的开销,同时优化数据访问模式,提高缓存命中率。
- A数组在这里通过寄存器存储是因为每次循环只涉及单个元素,而B数组的四列数据同时被访问,因此用指针遍历可以更灵活地处理多个元素,避免了寄存器的限制。这样也能减少对寄存器的竞争,提高计算的并行性。
源码
/* Create macros so that the matrices are stored in column-major order */
#define A(i,j) a[ (j)*lda + (i) ]
#define B(i,j) b[ (j)*ldb + (i) ]
#define C(i,j) c[ (j)*ldc + (i) ]
/* Routine for computing C = A * B + C */
void AddDot1x4( int, double *, int, double *, int, double *, int )
void MY_MMult( int m, int n, int k, double *a, int lda,
double *b, int ldb,
double *c, int ldc )
{
int i, j;
for ( j=0; j<n; j+=4 ){ /* Loop over the columns of C, unrolled by 4 */
for ( i=0; i<m; i+=1 ){ /* Loop over the rows of C */
/* Update C( i,j ), C( i,j+1 ), C( i,j+2 ), and C( i,j+3 ) in
one routine (four inner products) */
AddDot1x4( k, &A( i,0 ), lda, &B( 0,j ), ldb, &C( i,j ), ldc );
}
}
}
void AddDot1x4( int k, double *a, int lda, double *b, int ldb, double *c, int ldc )
{
/* So, this routine computes four elements of C:
C( 0, 0 ), C( 0, 1 ), C( 0, 2 ), C( 0, 3 ).
Notice that this routine is called with c = C( i, j ) in the
previous routine, so these are actually the elements
C( i, j ), C( i, j+1 ), C( i, j+2 ), C( i, j+3 )
in the original matrix C.
In this version, we use pointer to track where in four columns of B we are */
int p;
register double
/* hold contributions to
C( 0, 0 ), C( 0, 1 ), C( 0, 2 ), C( 0, 3 ) */
c_00_reg, c_01_reg, c_02_reg, c_03_reg,
/* holds A( 0, p ) */
a_0p_reg;
double
/* Point to the current elements in the four columns of B */
*bp0_pntr, *bp1_pntr, *bp2_pntr, *bp3_pntr;
bp0_pntr = &B( 0, 0 );
bp1_pntr = &B( 0, 1 );
bp2_pntr = &B( 0, 2 );
bp3_pntr = &B( 0, 3 );
c_00_reg = 0.0;
c_01_reg = 0.0;
c_02_reg = 0.0;
c_03_reg = 0.0;
for ( p=0; p<k; p++ ){
a_0p_reg = A( 0, p );
c_00_reg += a_0p_reg * *bp0_pntr++;
c_01_reg += a_0p_reg * *bp1_pntr++;
c_02_reg += a_0p_reg * *bp2_pntr++;
c_03_reg += a_0p_reg * *bp3_pntr++;
}
C( 0, 0 ) += c_00_reg;
C( 0, 1 ) += c_01_reg;
C( 0, 2 ) += c_02_reg;
C( 0, 3 ) += c_03_reg;
}Optimization8 优化 8
代码
/* Create macros so that the matrices are stored in column-major order */
#define A(i,j) a[ (j)*lda + (i) ]
#define B(i,j) b[ (j)*ldb + (i) ]
#define C(i,j) c[ (j)*ldc + (i) ]
/* Routine for computing C = A * B + C */
void AddDot1x4( int, double *, int, double *, int, double *, int )
void MY_MMult( int m, int n, int k, double *a, int lda,
double *b, int ldb,
double *c, int ldc )
{
int i, j;
for ( j=0; j<n; j+=4 ){ /* Loop over the columns of C, unrolled by 4 */
for ( i=0; i<m; i+=1 ){ /* Loop over the rows of C */
/* Update C( i,j ), C( i,j+1 ), C( i,j+2 ), and C( i,j+3 ) in
one routine (four inner products) */
AddDot1x4( k, &A( i,0 ), lda, &B( 0,j ), ldb, &C( i,j ), ldc );
}
}
}
void AddDot1x4( int k, double *a, int lda, double *b, int ldb, double *c, int ldc )
{
/* So, this routine computes four elements of C:
C( 0, 0 ), C( 0, 1 ), C( 0, 2 ), C( 0, 3 ).
Notice that this routine is called with c = C( i, j ) in the
previous routine, so these are actually the elements
C( i, j ), C( i, j+1 ), C( i, j+2 ), C( i, j+3 )
in the original matrix C.
We now unroll the loop */
int p;
register double
/* hold contributions to
C( 0, 0 ), C( 0, 1 ), C( 0, 2 ), C( 0, 3 ) */
c_00_reg, c_01_reg, c_02_reg, c_03_reg,
/* holds A( 0, p ) */
a_0p_reg;
double
/* Point to the current elements in the four columns of B */
*bp0_pntr, *bp1_pntr, *bp2_pntr, *bp3_pntr;
bp0_pntr = &B( 0, 0 );
bp1_pntr = &B( 0, 1 );
bp2_pntr = &B( 0, 2 );
bp3_pntr = &B( 0, 3 );
c_00_reg = 0.0;
c_01_reg = 0.0;
c_02_reg = 0.0;
c_03_reg = 0.0;
for ( p=0; p<k; p+=4 ){
a_0p_reg = A( 0, p );
c_00_reg += a_0p_reg * *bp0_pntr++;
c_01_reg += a_0p_reg * *bp1_pntr++;
c_02_reg += a_0p_reg * *bp2_pntr++;
c_03_reg += a_0p_reg * *bp3_pntr++;
a_0p_reg = A( 0, p+1 );
c_00_reg += a_0p_reg * *bp0_pntr++;
c_01_reg += a_0p_reg * *bp1_pntr++;
c_02_reg += a_0p_reg * *bp2_pntr++;
c_03_reg += a_0p_reg * *bp3_pntr++;
a_0p_reg = A( 0, p+2 );
c_00_reg += a_0p_reg * *bp0_pntr++;
c_01_reg += a_0p_reg * *bp1_pntr++;
c_02_reg += a_0p_reg * *bp2_pntr++;
c_03_reg += a_0p_reg * *bp3_pntr++;
a_0p_reg = A( 0, p+3 );
c_00_reg += a_0p_reg * *bp0_pntr++;
c_01_reg += a_0p_reg * *bp1_pntr++;
c_02_reg += a_0p_reg * *bp2_pntr++;
c_03_reg += a_0p_reg * *bp3_pntr++;
}
C( 0, 0 ) += c_00_reg;
C( 0, 1 ) += c_01_reg;
C( 0, 2 ) += c_02_reg;
C( 0, 3 ) += c_03_reg;
}Optimization9 优化 9
/* Create macros so that the matrices are stored in column-major order */
#define A(i,j) a[ (j)*lda + (i) ]
#define B(i,j) b[ (j)*ldb + (i) ]
#define C(i,j) c[ (j)*ldc + (i) ]
/* Routine for computing C = A * B + C */
void AddDot1x4( int, double *, int, double *, int, double *, int )
void MY_MMult( int m, int n, int k, double *a, int lda,
double *b, int ldb,
double *c, int ldc )
{
int i, j;
for ( j=0; j<n; j+=4 ){ /* Loop over the columns of C, unrolled by 4 */
for ( i=0; i<m; i+=1 ){ /* Loop over the rows of C */
/* Update C( i,j ), C( i,j+1 ), C( i,j+2 ), and C( i,j+3 ) in
one routine (four inner products) */
AddDot1x4( k, &A( i,0 ), lda, &B( 0,j ), ldb, &C( i,j ), ldc );
}
}
}
void AddDot1x4( int k, double *a, int lda, double *b, int ldb, double *c, int ldc )
{
/* So, this routine computes four elements of C:
C( 0, 0 ), C( 0, 1 ), C( 0, 2 ), C( 0, 3 ).
Notice that this routine is called with c = C( i, j ) in the
previous routine, so these are actually the elements
C( i, j ), C( i, j+1 ), C( i, j+2 ), C( i, j+3 )
in the original matrix C.
We next use indirect addressing */
int p;
register double
/* hold contributions to
C( 0, 0 ), C( 0, 1 ), C( 0, 2 ), C( 0, 3 ) */
c_00_reg, c_01_reg, c_02_reg, c_03_reg,
/* holds A( 0, p ) */
a_0p_reg;
double
/* Point to the current elements in the four columns of B */
*bp0_pntr, *bp1_pntr, *bp2_pntr, *bp3_pntr;
bp0_pntr = &B( 0, 0 );
bp1_pntr = &B( 0, 1 );
bp2_pntr = &B( 0, 2 );
bp3_pntr = &B( 0, 3 );
c_00_reg = 0.0;
c_01_reg = 0.0;
c_02_reg = 0.0;
c_03_reg = 0.0;
for ( p=0; p<k; p+=4 ){
a_0p_reg = A( 0, p );
c_00_reg += a_0p_reg * *bp0_pntr;
c_01_reg += a_0p_reg * *bp1_pntr;
c_02_reg += a_0p_reg * *bp2_pntr;
c_03_reg += a_0p_reg * *bp3_pntr;
a_0p_reg = A( 0, p+1 );
c_00_reg += a_0p_reg * *(bp0_pntr+1);
c_01_reg += a_0p_reg * *(bp1_pntr+1);
c_02_reg += a_0p_reg * *(bp2_pntr+1);
c_03_reg += a_0p_reg * *(bp3_pntr+1);
a_0p_reg = A( 0, p+2 );
c_00_reg += a_0p_reg * *(bp0_pntr+2);
c_01_reg += a_0p_reg * *(bp1_pntr+2);
c_02_reg += a_0p_reg * *(bp2_pntr+2);
c_03_reg += a_0p_reg * *(bp3_pntr+2);
a_0p_reg = A( 0, p+3 );
c_00_reg += a_0p_reg * *(bp0_pntr+3);
c_01_reg += a_0p_reg * *(bp1_pntr+3);
c_02_reg += a_0p_reg * *(bp2_pntr+3);
c_03_reg += a_0p_reg * *(bp3_pntr+3);
bp0_pntr+=4;
bp1_pntr+=4;
bp2_pntr+=4;
bp3_pntr+=4;
}
C( 0, 0 ) += c_00_reg;
C( 0, 1 ) += c_01_reg;
C( 0, 2 ) += c_02_reg;
C( 0, 3 ) += c_03_reg;
}