Hello_World但是是.rs
文件的创建和打开【命令行版本】
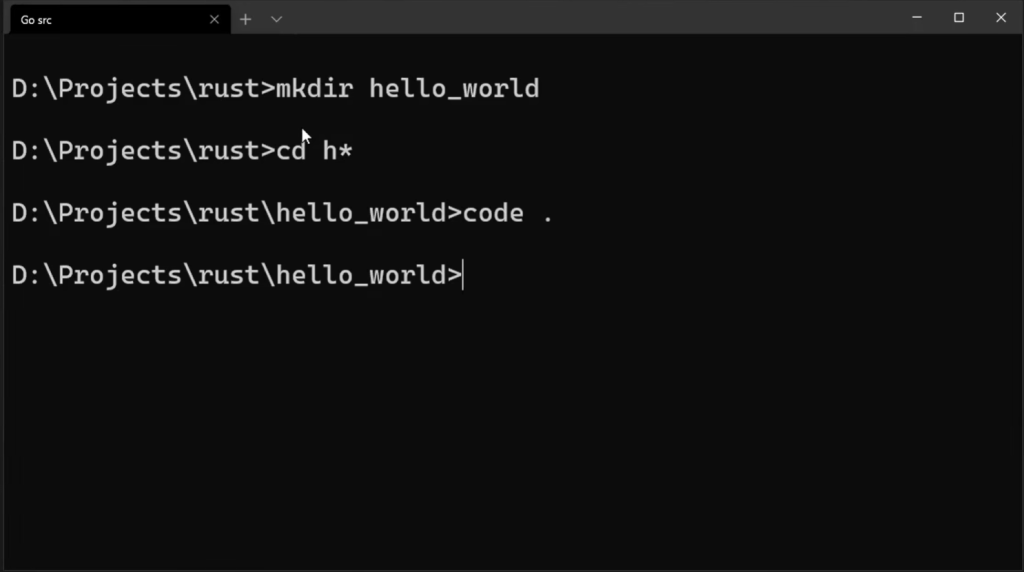
mkdir hello_worldmkdir在此目录下创建一个文件夹hello_world文件夹的名字cd h*cd进入某个目录h*匹配以字母h开头的目录或文件
名code .code .- 解释:
code是 Visual Studio Code 的命令行启动命令,后面的.表示当前目录。 - 作用:该命令在当前目录
hello_world中打开 Visual Studio Code,并将该目录作为工作区加载。
- 解释:
在软件中创建rust文件
注意:rust文件的后缀是.rs
编译与运行rust程序
假如文件名是main.rs
编译文件
编译需要在terminal中输入rustc main.rs//c是编译器的简compiler
其中main需要替换成你需要编译的目标文件名
运行文件
运行需要在terminal中输入.\main.exe
Windows版本
其中main需要替换成你需要编译的目标文件名./main
Linux/mac版本
其中main需要替换成你需要编译的目标文件名
问题
PS:老师的演示是直接输入文件名
main便编译成功,但是我这边却不能实现【还没去查这是为什么?】
【注意】 必须要手动编译,然后手动运行
最重要的一些基础概念
[!note] 碎碎念
我靠!!!这什么抽象的概念,还涉及到语言的底层设计???
我建议/想法是先往后面看,等后面边学边练边看迭代器
在 Rust 中,迭代器(iterator)是一种设计模式,用于在一个集合(如数组、向量、哈希表等)上进行逐个访问或遍历操作,而不需要显式地管理索引或迭代逻辑。迭代器提供了一种高效、可组合的方式来处理数据流和集合。
Rust 迭代器概念
Rust 的迭代器遵循了 惰性评估 的原则,即在调用方法时不会立即执行操作,直到显式消耗该迭代器(如通过 for 循环或消耗方法如 collect())。Rust 中的迭代器可以通过 Iterator 特性(trait)来表示。
Iterator 特性
在 Rust 中,Iterator 特性定义了迭代器的行为,它包含一个核心方法 next(),用于从迭代器中依次获取每个元素。当迭代器到达末尾时,next() 返回 None,表示迭代已经结束。
定义:
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
// 其他常用的方法如 `map`, `filter`, `fold` 等
}Item:迭代器产生的元素的类型。next():每次调用时返回Some(Item),如果没有更多元素,返回None。
创建迭代器
在 Rust 中,常见的集合类型,如数组、向量、切片等,都可以生成迭代器。可以通过 .iter() 方法来创建一个迭代器,或者用 .into_iter() 消耗所有权来创建。
示例:
fn main() {
let v = vec![1, 2, 3];
// 创建一个不可变迭代器
let mut iter = v.iter();
// 逐个获取元素
assert_eq!(iter.next(), Some(&1));
assert_eq!(iter.next(), Some(&2));
assert_eq!(iter.next(), Some(&3));
assert_eq!(iter.next(), None); // 没有更多元素,返回 None
}消耗迭代器
迭代器通常通过一些方法来被消耗,最常见的是通过 for 循环来逐个获取元素。Rust 自动调用迭代器的 next() 方法来逐一消耗。
使用 for 循环:
fn main() {
let v = vec![10, 20, 30];
for value in v.iter() {
println!("{}", value); // 输出每个元素
}
}迭代器适配器
Rust 中的迭代器非常强大,因为它们可以被链式调用来进行各种操作,比如过滤、映射、折叠等。这些链式方法被称为迭代器适配器,它们不会立即消耗迭代器,而是返回一个新的迭代器,可以进一步操作或最后消耗。
一些常见的迭代器适配器包括:
map:对每个元素应用一个函数,返回一个新的迭代器。filter:只保留满足某个条件的元素。enumerate:将元素与索引一起返回。fold:将迭代器中的元素聚合为一个单一值。
示例:
fn main() {
let v = vec![1, 2, 3, 4, 5];
// 使用 map 和 filter 对迭代器进行操作
let result: Vec<i32> = v.iter()
.map(|x| x * 2) // 每个元素乘以 2
.filter(|x| *x > 5) // 只保留大于 5 的元素
.collect(); // 收集为 Vec
println!("{:?}", result); // 输出 [6, 8, 10]
}消耗适配器
迭代器的消耗方法会真正执行迭代操作并将结果消耗掉,例如 collect()、count()、sum() 等方法会立即产生结果。
collect():将迭代器转化为集合类型,如Vec、HashMap等。sum():对迭代器中所有元素求和。count():计算迭代器中元素的数量。
示例:
fn main() {
let v = vec![1, 2, 3, 4, 5];
// 对迭代器求和
let sum: i32 = v.iter().sum();
println!("Sum: {}", sum); // 输出 Sum: 15
}总结
Rust 中的迭代器是一种非常灵活、强大的工具,支持惰性评估、链式调用和组合操作。通过 Iterator 特性和丰富的迭代器适配器,可以轻松实现对集合的高效操作,避免复杂的手动遍历逻辑。
所有权
Rust 中的 所有权(Ownership)系统是该语言的核心特色之一,它帮助开发者在编译时管理内存,并防止数据竞争、空指针、悬垂指针等问题。Rust 不依赖垃圾回收(GC),也不需要手动分配和释放内存,所有这些内存管理细节都是通过所有权系统来完成的。
所有权的基本规则
Rust 的所有权系统基于三个核心规则:
- 每个值都有一个所有者(Owner)。
- 每个值在同一时间只能有一个所有者。
- 当所有者离开作用域时,值会被释放(dropped)。
作用域与堆栈
要理解 Rust 的所有权,首先要理解作用域的概念。作用域决定了变量的生命周期,即变量何时被创建,何时失效。
{
let s = String::from("hello"); // s 在这里进入作用域
// 使用 s
} // 这个作用域结束后,s 被自动释放在这个例子中,String::from("hello") 创建了一个 String 类型的值。这个 String 分配在堆上,而变量 s 是堆上数据的所有者。一旦 s 离开作用域,Rust 会自动调用 drop 函数释放这个 String 的堆内存。
移动语义(Move Semantics)
在 Rust 中,当赋值或传递变量时,所有权会发生转移,称为 移动(Move)。当一个变量的所有权转移后,原来的变量将不再有效,不能再使用。
fn main() {
let s1 = String::from("hello");
let s2 = s1; // s1 的所有权被移动到 s2
// println!("{}", s1); // 错误!s1 不再有效
println!("{}", s2); // 输出 "hello"
}在这个例子中,s1 的所有权被移动给了 s2。因为 Rust 的所有权系统不允许多个所有者,所以在 s1 的所有权被转移后,s1 将不再有效。
深拷贝与克隆(Clone)
如果想要保留源变量的值并且允许多个变量持有同一个值,可以使用 克隆(clone())来显式地进行深拷贝。
fn main() {
let s1 = String::from("hello");
let s2 = s1.clone(); // 这里发生了深拷贝
println!("s1 = {}, s2 = {}", s1, s2); // s1 和 s2 都有效
}调用 clone() 会将堆上的数据完全复制,因此 s1 和 s2 是两个独立的所有者。
栈上数据的拷贝行为
对于像 i32 这样存储在栈上的基本类型,Rust 实现了 Copy 特性。与堆上数据不同,栈上数据不会被移动,而是被简单复制。这意味着赋值操作不会转移所有权,原变量仍然有效。
fn main() {
let x = 5;
let y = x; // 这里发生了复制,而不是移动
println!("x = {}, y = {}", x, y); // x 和 y 都有效
}Rust 的一些基本类型,如整数、浮点数、布尔值、字符等都实现了 Copy 特性,因为它们存储在栈上,复制的开销很小。
所有权与函数
所有权在函数参数传递时也会发生移动。将值传递给函数时,所有权会转移给函数的参数,函数执行完成后,值会被释放。如果希望在函数调用后继续使用传递的值,必须返回所有权。
fn main() {
let s = String::from("hello");
take_ownership(s); // s 的所有权被移动到函数内
// println!("{}", s); // 错误!s 的所有权已被转移
}
fn take_ownership(some_string: String) {
println!("{}", some_string);
} // some_string 在这里被释放返回所有权
在 Rust 中,如果需要将一个值返回给调用者以保留所有权,必须显式地返回它。
fn main() {
let s1 = gives_ownership(); // gives_ownership 返回值给 s1
let s2 = String::from("hello");
let s3 = takes_and_gives_back(s2); // s2 的所有权被移动给 s3
// println!("{}", s2); // 错误!s2 的所有权已经被转移
}
fn gives_ownership() -> String {
let some_string = String::from("hello");
some_string // 返回 some_string 的所有权
}
fn takes_and_gives_back(a_string: String) -> String {
a_string // 返回 a_string 的所有权
}借用(Borrowing)与引用
所有权系统还有一个重要的概念是 借用(Borrowing),即你可以通过 引用(reference)来访问变量的值,而不会转移所有权。Rust 提供了两种借用方式:不可变借用(&T)和可变借用(&mut T)。
不可变引用
不可变引用允许你读取数据,但不能修改。并且在同一时间,你可以创建多个不可变引用。
fn main() {
let s = String::from("hello");
let r1 = &s; // 不可变借用
let r2 = &s; // 允许多个不可变借用
println!("{} and {}", r1, r2);
} // r1 和 r2 在这里被释放,但它们不拥有 s,所以没有影响可变引用
可变引用允许你修改数据,但同一时间只能有一个可变引用,且不能与不可变引用共存。这是为了防止数据竞争。
fn main() {
let mut s = String::from("hello");
let r1 = &mut s; // 可变借用
r1.push_str(", world");
println!("{}", r1); // 输出 "hello, world"
}借用规则
Rust 的借用系统有以下几个重要规则:
- 在任意给定时间,只能有一个可变引用,或者多个不可变引用,但不能同时存在。
- 引用必须总是有效的,即引用的变量在引用的整个生命周期内必须有效。
总结
Rust 的所有权系统通过以下几种方式帮助开发者管理内存:
- 所有权转移:通过变量赋值或函数参数传递,所有权会发生移动,避免了多个变量拥有同一块内存的情况。
- 借用与引用:通过借用机制,允许多个地方读取同一个值,同时避免数据竞争和悬垂指针。
- 自动释放:当变量离开作用域时,Rust 会自动释放相应的内存,避免了手动内存管理。
这些特性使得 Rust 能够在编译时保证内存安全,同时无需依赖垃圾回收器。
变量绑定
[!note] 摘自圣经
在其它语言中,我们用var a = "hello world"的方式给a赋值,也就是把等式右边的"hello world"字符串赋值给变量a,而在 Rust 中,我们这样写:let a = "hello world",同时给这个过程起了另一个名字:变量绑定。为何不用赋值而用绑定呢(其实你也可以称之为赋值,但是绑定的含义更清晰准确)?这里就涉及 Rust 最核心的原则——所有权,简单来讲,任何内存对象都是有主人的,而且一般情况下完全属于它的主人,绑定就是把这个对象绑定给一个变量,让这个变量成为它的主人(聪明的读者应该能猜到,在这种情况下,该对象之前的主人就会丧失对该对象的所有权),像极了我们的现实世界,不是吗?
那为什么要引进“所有权”这个新的概念呢?请稍安勿躁,时机一旦成熟,我们就回来继续讨论这个话题。
元组
元组(Tuple)是一种将多个值组合成一个单一复合值的数据结构。在许多编程语言中,元组被用来同时返回多个值或存储不同类型的数据。
在 Rust 语言中,元组是一个固定大小的、不同类型的值的有序集合。元组可以用圆括号 () 包围,并且其中的元素通过逗号 , 分隔。例如:
let x: (i32, f64, u8) = (20, 30.5, 255);在这个例子中,我们创建了一个元组 x,它包含三个不同类型的元素:一个 32 位整数 i32,一个 64 位浮点数 f64,和一个 8 位无符号整数 u8。
Rust 中的元组特性包括:
- 大小固定:一旦创建,元组的大小不能改变。
- 类型多样:元组中的每个元素可以是不同的类型。
- 有序:元组中的元素有特定的顺序,可以通过位置索引来访问。
- 解构:可以一次性将元组中的值解构赋值给多个变量。
- 模式匹配:可以在
match表达式中使用模式匹配来处理元组。
以下是一些使用元组的示例:
- 访问元组元素:通过模式匹配或下标操作符
[]访问元组中的元素。
let tuple = (1, 2, 3);
let first_item = tuple.0; // 使用下标访问
let (a, b, c) = tuple; // 使用模式匹配解构- 解构元组:
let tuple = (1, 2, 3);
let (x, y, z) = tuple;
println!("x = {}, y = {}, z = {}", x, y, z);- 元组作为函数返回值:
fn calculate() -> (i32, i32, i32) {
let a = 1;
let b = 2;
let c = a + b;
(a, b, c)
}
let (a, b, c) = calculate();
println!("a = {}, b = {}, c = {}", a, b, c);元组在 Rust 中非常有用,尤其是在需要将多个值组合在一起或从函数返回多个值时。
切片
[!note] 总结:
在 Rust 中,切片(slice) 是对某个集合(比如数组或字符串)的连续部分的引用。切片不拥有数据本身,而是引用数据的一部分,因此切片的大小是动态的,可以用来访问集合的部分内容,而不会复制或移动数据。
特点:
- 切片可以看作是对数组、字符串、向量等可索引类型的借用。
- 切片是 不可变 或 可变 的(对应
&[T]和&mut [T]类型)。 - 切片允许你安全地引用集合的一部分,并且长度在运行时确定。
语法
使用 引用符号加上数组的区间 来创建一个切片。例如,如果你有一个数组 arr,你可以创建一个切片 &arr[start..end],它包含从 start 到 end-1 索引位置的元素。
示例代码:
fn main() {
let arr = [1, 2, 3, 4, 5];
// 创建一个不可变切片,包含数组中的第1到第3个元素
let slice = &arr[1..4];
println!("切片内容: {:?}", slice);
}输出:
切片内容: [2, 3, 4]在这个例子中,切片 &arr[1..4] 包含了数组 arr 中索引为 1 到 3 的元素,即 [2, 3, 4]。
字符串切片
字符串切片也是一种切片,常见的形式是 &str 类型,它是对 String 的引用。
fn main() {
let s = String::from("hello world");
// 获取 "hello" 部分的切片
let hello = &s[0..5];
println!("切片: {}", hello);
}注意:
- 切片只引用原始数据的一部分,不会创建新副本,因此它们非常高效。
- 切片使用时的范围必须是有效的,否则会发生运行时错误(越界错误)。
总结来说,Rust 中的切片提供了一种高效、安全的方式来引用集合的一部分数据,而不会移动或复制数据本身。
函数的调用
在 Rust 中,函数的调用方式有多种。是否使用 .函数() 的形式 取决于函数的种类和变量的类型:
1. 普通函数调用:
普通函数是在程序的作用域中定义的,它直接通过函数名进行调用,不涉及变量或对象。例如:
fn say_hello() {
println!("Hello, world!");
}
fn main() {
say_hello(); // 直接调用普通函数
}2. 方法调用(method calls):
方法是与某个特定类型关联的函数,通常定义在一个类型的 impl 块中。这种方法需要通过对象(变量)来调用,语法是 对象.方法()。
例如,字符串类型有很多方法可以使用:
fn main() {
let s = String::from("hello");
println!("{}", s.len()); // 通过 .len() 调用方法,返回字符串的长度
}在这个例子中,s.len() 是一个 方法调用,len() 是 String 类型的一个方法,通过变量 s 调用。
3. 链式调用:
Rust 允许通过链式调用来连续执行多个方法。这种情况通常涉及到返回值是某个对象,可以继续调用该对象的其他方法。例如:
fn main() {
let s = String::from(" hello ");
let trimmed = s.trim().to_uppercase(); // 链式调用 .trim() 和 .to_uppercase()
println!("{}", trimmed); // 输出 "HELLO"
}s.trim()去掉了字符串两端的空白。- 返回的结果又调用了
to_uppercase(),将字符串转为大写。
4. 静态方法调用:
静态方法通过类型名调用,而不是通过实例。语法是 TypeName::method()。
例如:
fn main() {
let n = i32::from_str_radix("A", 16).unwrap(); // 通过类型 i32 调用 from_str_radix 静态方法
println!("{}", n); // 输出 10
}总结:
- 普通函数 直接调用,不需要通过变量。
- 方法 是绑定在某个类型上的函数,使用
变量.方法()的方式调用。 - 链式调用 是连续调用方法,返回值仍然可以调用后续方法。
- 静态方法 通过类型名调用,而不是通过实例。
Rust 中的 .函数() 形式专门用于调用与类型相关联的方法(method),而不是所有的函数。
as 数据类型转化的关键字
在 Rust 中,数据类型的转换可以通过 显式类型转换 来实现。对于整数类型之间的转换,Rust 提供了 as 关键字,用于将一种类型的值转换为另一种类型。
例如,从 i16 转换为 u16,可以这样做:
fn main() {
let a: i16 = -5;
// 将 i16 类型的 a 转换为 u16
let b: u16 = a as u16;
println!("a = {}, b = {}", a, b);
}as 关键字的作用:
- 安全转换:将一种数据类型显式转换为另一种类型。
- 整数类型转换:可以用来在有符号整数(如
i16)和无符号整数(如u16)之间进行转换。
注意事项:
- 值的范围问题:转换时,如果值超出了目标类型的范围,Rust 不会报错,但会发生截断或其他形式的溢出行为。
- 例如:当你将负数从
i16转换为u16时,负数的二进制表示将直接转换为无符号的值。例如,-5i16的二进制形式为1111 1011,被转换为65531u16。
fn main() {
let a: i16 = -5;
let b: u16 = a as u16; // 这里会截断并得到 65531
println!("a = {}, b = {}", a, b);
}- 浮点数与整数之间的转换:使用
as关键字可以将浮点数转换为整数(反之亦然),但转换时会丢失小数部分。
fn main() {
let x: f32 = 3.99;
let y: i32 = x as i32; // 小数部分会被舍弃,结果为 3
println!("x = {}, y = {}", x, y);
}更安全的转换方式:
如果你想要更加安全地进行类型转换(例如检查是否超出了范围),可以使用 std::convert::TryFrom 和 std::convert::TryInto。
use std::convert::TryInto;
fn main() {
let a: i16 = -5;
// 尝试将 i16 转换为 u16,如果值超出范围,转换将失败
let b: Result<u16, _> = a.try_into();
match b {
Ok(value) => println!("转换成功: {}", value),
Err(e) => println!("转换失败: {:?}", e),
}
}在这种方式下,程序会在超出范围时返回错误,确保转换的安全性。
泛型
泛型(Generics)是一种编程语言的特性,允许编写能够适用于多种数据类型的代码,而不需要在编写时指定具体的类型。通过使用泛型,可以创建更灵活、可重用的代码,从而减少代码的重复。
在很多编程语言(如 Rust、C++、Java 等)中,泛型允许函数、结构体、枚举或特性(traits)等能够处理不同类型的数据,而无需为每种数据类型都编写单独的实现。
为什么需要泛型?
假设你想编写一个函数,它可以处理不同类型的数据,如整数、浮点数、字符串等。如果不使用泛型,可能需要为每个数据类型编写一个函数,像这样:
fn add_i32(x: i32, y: i32) -> i32 {
x + y
}
fn add_f64(x: f64, y: f64) -> f64 {
x + y
}这是低效的,因为对于每个可能的数据类型,代码都需要重复一遍。泛型通过引入一种“占位符”类型,允许你编写一次函数,就能适用于多种数据类型。
泛型的使用示例
在 Rust 中,可以通过尖括号 <> 定义泛型。例如,一个泛型的加法函数可以这样写:
fn add<T: std::ops::Add<Output = T>>(x: T, y: T) -> T {
x + y
}代码详解:
fn add<T>:这里的T是一个泛型类型参数,表示可以接受任意类型。T: std::ops::Add<Output = T>:这是对泛型的约束,表示T必须实现Addtrait,且加法的输出结果也是T类型。这个约束确保T类型支持加法运算。x: T, y: T -> T:这个函数接受两个相同类型的参数x和y,并返回它们的和,类型同样是T。
通过这个函数,add 函数可以适用于任意实现了加法操作的类型,例如 i32、f64 或其它自定义类型。
泛型的优势
- 代码重用:只需编写一次函数或类型,就能适用于多种数据类型,减少代码重复。
- 类型安全:泛型在编译时会被替换为实际的具体类型,所以不会影响性能,同时仍然保持了类型检查的严格性。
- 灵活性:泛型支持编写更加抽象和灵活的代码,允许你在保持通用性的同时仍然保证类型的安全性。
泛型在结构体中的使用
泛型不仅可以用于函数,还可以用于结构体、枚举等数据结构。例如,在 Rust 中,你可以创建一个支持泛型的结构体:
struct Point<T> {
x: T,
y: T,
}
fn main() {
let integer_point = Point { x: 5, y: 10 };
let float_point = Point { x: 1.0, y: 4.0 };
}在这个例子中,Point 结构体可以存储任意类型的 x 和 y,例如整数或浮点数。
泛型的类型约束
泛型允许添加类型约束来限制泛型的类型。这样可以确保泛型只能是某些特定的类型。例如:
fn print_display<T: std::fmt::Display>(item: T) {
println!("{}", item);
}这里的 T: std::fmt::Display 限制了 T 必须实现 Display trait,这样可以确保传入的类型可以使用 {} 进行格式化输出。
总结
泛型提供了一种编写通用代码的能力,适用于多种数据类型。通过泛型,代码不仅更具灵活性,还能够避免重复实现,提升代码的可维护性与可扩展性。
基本类型
[!note] 注意点
i8指的是有符号的8位【二进制】整数
- 数值类型:有符号整数 (
i8,i16,i32,i64,isize)、 无符号整数 (u8,u16,u32,u64,usize) 、浮点数 (f32,f64)、以及有理数、复数- 字符串:字符串字面量和字符串切片
&str- 布尔类型:
true和false- 字符类型:表示单个 Unicode 字符,存储为 4 个字节
- 单元类型:即
(),其唯一的值也是()第一个程序:Hello_World
代码:
fn greet_world()
{
let southern_germany = "Grüß Gott!";
let chinese = "世界,你好";
let english = "World, hello";
let regions = [southern_germany, chinese, english];
for region in regions.iter()
{
println!("{}",®ion);
}
}
fn main()
{
greet_world();
}第二个程序:???抽象
fn main()
{
let penguin_data = "\
common name,length (cm)
Little penguin,33
Yellow-eyed penguin,65
Fiordland penguin,60
Invalid,data
";
let records = penguin_data.lines();
for (i, record) in records.enumerate()
{
if i == 0 || record.trim().len() == 0
{
continue;
}
// 声明一个 fields 变量,类型是 Vec
// Vec 是 vector 的缩写,是一个可伸缩的集合类型,可以认为是一个动态数组
// <_>表示 Vec 中的元素类型由编译器自行推断,在很多场景下,都会帮我们省却不少功夫
let fields: Vec<_> = record
.split(',')
.map(|field| field.trim())
.collect();
if cfg!(debug_assertions)
{
// 输出到标准错误输出
eprintln!("debug: {:?} -> {:?}",
record, fields);
}
let name = fields[0];
// 1. 尝试把 fields[1] 的值转换为 f32 类型的浮点数,如果成功,则把 f32 值赋给 length 变量
//
// 2. if let 是一个匹配表达式,用来从=右边的结果中,匹配出 length 的值:
// 1)当=右边的表达式执行成功,则会返回一个 Ok(f32) 的类型,若失败,则会返回一个 Err(e) 类型,if let 的作用就是仅匹配 Ok 也就是成功的情况,如果是错误,就直接忽略
// 2)同时 if let 还会做一次解构匹配,通过 Ok(length) 去匹配右边的 Ok(f32),最终把相应的 f32 值赋给 length
//
// 3. 当然你也可以忽略成功的情况,用 if let Err(e) = fields[1].parse::<f32>() {...}匹配出错误,然后打印出来,但是没啥卵用
if let Ok(length) = fields[1].parse::<f32>()
{
// 输出到标准输出
println!("{}, {}cm", name, length);
}
}
}第三个程序:Mut可变类型
[!note] 重点
Rust 的变量在默认情况下是不可变的
但是可以通过mut关键字让变量变为可变的
代码:
fn main()
{
let mut x = 5;
println!("The Value of x is {}",x);
x = 6;
println!("The Value of x is {}",x);
}一些函数
type_of(变量地址)
这段 Rust 代码定义了一个泛型函数 type_of<T>,用于获取传入参数的类型并返回其类型名称的字符串表示。让我们详细解析其中的每个部分:
fn type_of<T>(_: &T) -> String {
format!("{}", std::any::type_name::<T>())
}1. 泛型类型 T:
T是一个泛型参数,表示该函数可以接受任意类型的参数,而不仅仅是某一种特定类型。例如,这个函数可以接受i32、f64、String等类型。fn type_of<T>(_: &T)中,<T>表示函数接受一个类型参数T,它可以是任何类型。
2. 参数 _:
- 参数
_是函数的形式参数,它接受一个对T类型的引用(&T)。 _这个名字特别之处在于:前导下划线表示这个参数不会在函数体中被使用。Rust 允许你在不使用变量时加上_,以避免编译器发出“未使用变量”的警告。- 该参数的目的是提供一个
T类型的实际值,以便 Rust 在编译时确定T的实际类型。
3. 返回值类型 String:
- 函数返回值是
String,表示返回的值是一个字符串类型,具体为参数类型的字符串表示。
4. std::any::type_name::<T>():
std::any::type_name::<T>()是标准库std::any中的函数,它返回类型T的名称,格式是静态字符串(&'static str),即类型名称的字面量。::<T>语法用于指定类型参数T,告诉 Rust 需要获取泛型T的类型名。
5. format! 宏:
format!是一个格式化宏,类似于println!,但不同之处在于它返回一个String,而不是直接输出。format!("{}", ...)将类型名称插入到字符串中,最终将其返回为String类型。
例子:
fn main() {
let x = 10u32;
println!("{}", type_of(&x)); // 输出 "u32"
}在这个例子中,type_of 函数获取了变量 x 的类型,并返回类型名称 "u32"。
总结:
type_of<T> 函数的作用是接收一个值的引用,并返回该值的类型名称,封装成 String 类型。这对于调试或反射场景(查看数据类型)非常有用。
Rust 语言中的注释符号
一些基本知识
//后面跟注释的内容/*中间跟注释的内容*/
是的,rust中的注释符号和C、C++中的符号一致
问题
【问题】 为什么这个编译无法完成?——在看了借用和引用后再回看这个问题