前言
本系列是基于 sonder 的博客内容的学习笔记,既是作为学习记录,也是完善这个难得的高质教程,为后来者铺路。
此文档面向的是 CUDA 编程的新手或希望了解GPU硬件架构的读者,由浅入深阐述 GPU 硬件架构、 CUDA 并行编程模型、基本概念和语言特点,期望在以下方面对读者有所裨益:
- 能知道 GPU 一般硬件架构并和软件层进行联系
- 能帮助读懂一个复杂 Kernel 的实现逻辑,具备 CUDA 编程思维
- 能帮助判断一个 kernel 是计算密集型还是访存密集型
- 能掌握部分算子优化方法以及进一步优化方法
- 能以此为跳板,具备自主深入调研、系统学习CUDA优化方法论,具备写 Demo 验证的能力
术语释意
设备
主机
SEME(SHARE MEMORY)
CACHE LINE
DRAM
动态随机存取存储器
WARP
纹理内存
指令缓存器
CLK
CUDA 硬件架构
所有的优化出发点都是为了更加高效地压榨硬件性能,因此开始优化之前需要先掌握设备的硬件架构
由于不同的GPU架构不同,SM中的组成单元的类型和数量也会不同,但总体而言相差不是很大(除非硬件架构相差特别大),这里以A100为例进行说明
存储硬件 Part
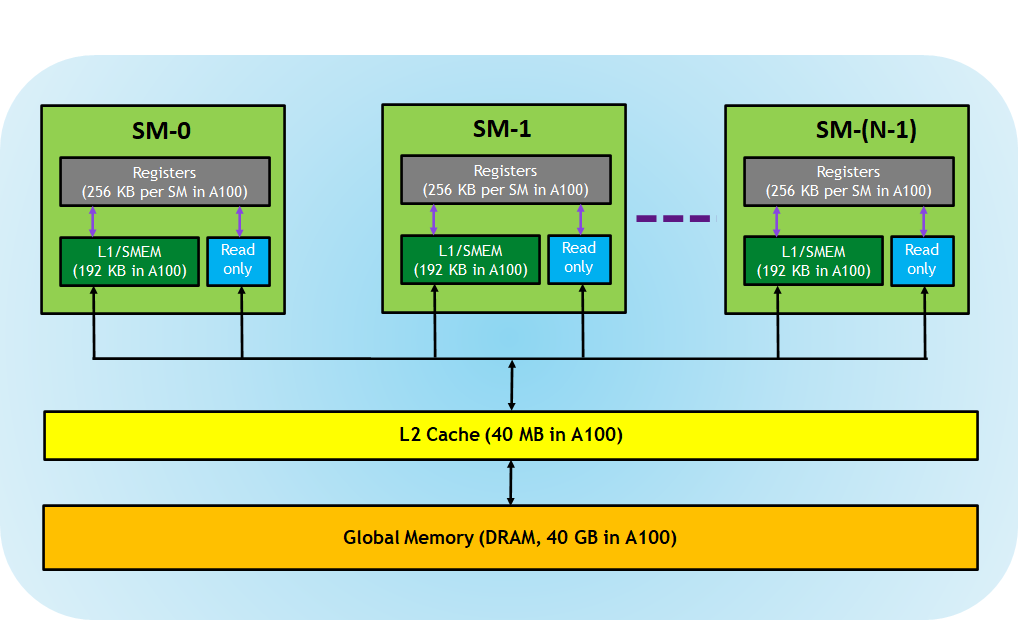
GPU 中最小的功能单元是 SM(Streaming Multiprocessor,流式多处理器),在 SM 外通过 L2 (cache line 2)以及 Global Memory(DRAM)进行数据交换
SM中包括
- 寄存器(register)
- cache line 1(简称L1)
- share memory
- 只读内存(还可以细分)
Register
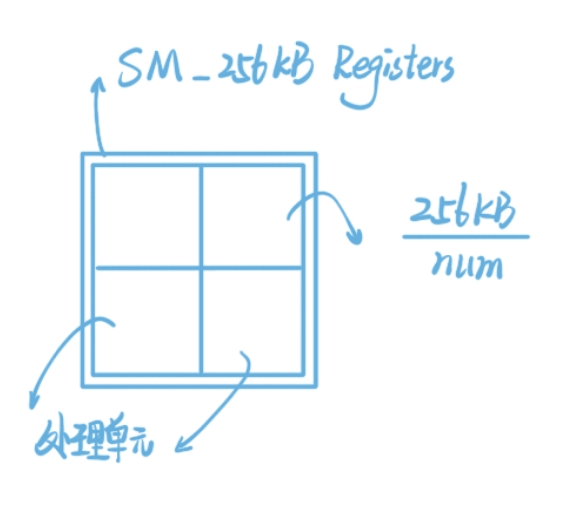
注意,一个 SM 的寄存器数量是一定的,SM中的寄存器会均分给里面的处理块,每个处理块中的寄存器自有进行分配。
每个 thread 专用,这意味着分配给该线程的寄存器对其他线程不可见,编译器做出有关寄存器利用率的决策(或者在程序中使用关键词、内联汇编等方式自主利用寄存器)。 * L1/Shared memory (SMEM):每个 SM 都有一个快速的 on-chip scratched 存储器,可用作 L1 cache 和 shared memory。CUDA block 中的所有线程可以共享 shared memory,并且在给定 SM 上运行的所有 CUDA Block 可以共享 SM 提供的物理内存资源。
Cache Line 1
Share Memory
只读内存
纹理内存
常量内存
附语
- 解释一下为什么空间越小访存越快【可以使用导论中的工厂的例子】
SM 硬件组成
这里阐述 SM 硬件的具体组成
SM 中由一定的处理块组成,从图中可以看见 A100 的一个 SM 由4个处理块组成
可以看见一个 SM 中有:
公用的:
- 纹理内存
- L1 Data cache 和 share memory(这里是同一硬件的不同名还是不同硬件?)
- L1 introduction cache
处理块内私有的:
- L0introduction cache
- Warp scheduler
- dispatch unit
- register file
块内的计算硬件:
- int32
- fp32
- fp64
- tensor core
- LD/ST
- SFU


