
本文最后更新于247 天前,其中的信息可能已经过时,如有错误请发送邮件到zhangweihao22@outlook.com
为什么声明一个数组A_d,取数组的地址传入cudaMalloc却产生报错?
已知:cudaMalloc 函数传入的第一个参数应该为指向指针的指针【**p】
而改为传入(int **)A_d则不产生报错?
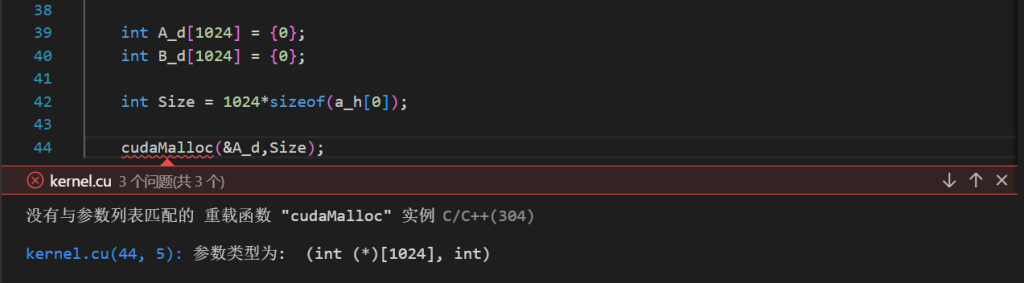
(int **)A_d是强制类型转化,转化为正确的形参类型【那么之后的内存分配是否按照设想的方式给A_d数组分配指定Size大小的设备空间?
我觉得是没有问题的,因为cudaMalloc函数本身的意思可能就是为被指向的那个指针开辟一段指定大小的空间,后面可以以那个指针为初始索引进行数据的读入和读取【先试试】
为什么下面的代码会报错
kernel.cu(71): error: expression must have integral or unscoped enum type
Test_add<<blocksPerGrid,threadPerBlock>>(a_d,b_d,end_d,1024);
^#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include<cuda_runtime.h>
#include <stdio.h>
#include <time.h>
#define Size 1024
__global__ void Test_add(int *A,int *B,int *end,int size)
{
int i = blockDim.x*blockIdx.x+threadIdx.x; // 获得线性【全局】索引
// 检查索引是否在处理范围内
if(i < size)
{
end[i] = A[i] + B[i];
}
}
int main()
{
clock_t start, end;
double cpu_time_used;
start = clock();
// 在这里放置您想要计时的代码
// 例如,可以是一些计算或处理任务
int a_h[Size] = {0};
int b_h[Size] = {0};
int end_h[Size] = {0};
for(int i = 0 ; i < Size ; i ++)
{
a_h[i] = i + 1;
b_h[i] = (i+1) * 2;
}
// 打印a,b数组的数据
for(int k = 0 ; k < Size/8 ; k += 8)
{
printf("%d %d %d %d %d %d %d %d\n",a_h[k],a_h[k+1],a_h[k+2],a_h[k+3],a_h[k+4],a_h[k+5],a_h[k+6],a_h[k+7]);
}
for(int k = 0 ; k < Size/8 ; k += 8)
{
printf("%d %d %d %d %d %d %d %d\n",b_h[k],b_h[k+1],b_h[k+2],b_h[k+3],b_h[k+4],b_h[k+5],b_h[k+6],b_h[k+7]);
}
int a_d[Size] = {0};
int b_d[Size] = {0};
int end_d[Size] = {0};
// 参考代码是声明的一个指针而不是数组
int size_space = Size*sizeof(a_h[0]);
cudaMalloc((int **)&a_d,Size);
cudaMalloc((int **)&b_d,Size);
cudaMalloc((int **)&end_d,Size);
cudaMemcpy(a_h,a_d,size_space,cudaMemcpyHostToDevice);
cudaMemcpy(b_h,b_d,size_space,cudaMemcpyHostToDevice);
unsigned int threadPerBlock = 256;
unsigned int blocksPerGrid = (Size + threadPerBlock)/threadPerBlock; // 向上取整获取线程块数目
// 启动内核函数
Test_add<<blocksPerGrid,threadPerBlock>>(a_d,b_d,end_d,Size);
cudaMemcpy(end_h,end_d,size_space,cudaMemcpyDeviceToHost);
for(int k = 0 ; k < Size/8 ; k += 8)
{
printf("%d %d %d %d %d %d %d %d\n",end_h[k],end_h[k+1],end_h[k+2],end_h[k+3],end_h[k+4],end_h[k+5],end_h[k+6],end_h[k+7]);
}
cudaFree(a_d);
cudaFree(b_d);
cudaFree(end_d);
end = clock();
cpu_time_used = ((double) (end - start)) / CLOCKS_PER_SEC;
printf("Time taken: %f seconds\n", cpu_time_used);
return 0;
}
