前言
本文起始于一个令人感到bored的问题:在windows系统下的vscode上进行cuda程序编译运行时,终端中输出的中文文字替换为讨厌的乱码
这对于我而言是难以忍受的,因为这破坏了一个程序的美感:
brief coding , quick compiling and readily comprehensible output .
于是去寻找一些解决方法。
暂时解决问题后,写下这篇文章记录 the way to deal with the issue 并予后来人可用的方案
解决方案
解决方案大致分为以下几种:
- 更改文件编码方式
- 调用
<windows.h>库,指定终端输出编码格式 - 在.vscode设置文件添加默认编码格式指令
更改文件编码方式
这个方法说来奇怪,是在我之前进行c语言编程的时候在vscode上面遇到的同这个相同问题时候的解决方法,但是目前再来使用却解决不了问题(也许是我记错了问题出现的环境了?)。大体解决思路如下:
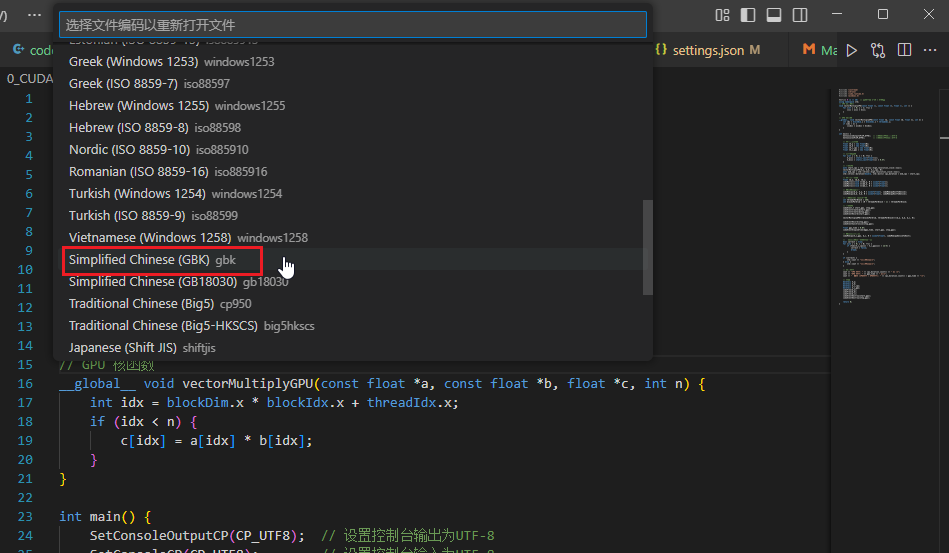
- 点击vscode页面右下角的编码格式
- 选择通过编码重新打开
- 选择GBK编码格式打开
- Ctr + Z 进行撤回
- 编译运行(正常显示)
我这里这个方法失效了,因此无法给出最终正常运行的截图
不过之前我的机器使用这个方法是可行的
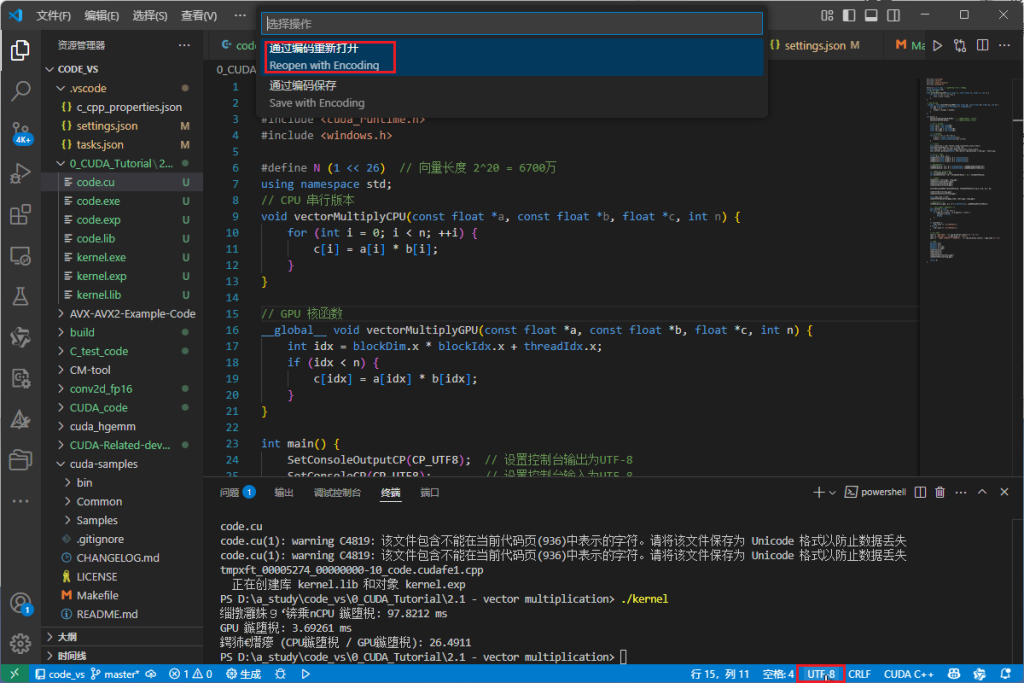
调用<windows.h>库,指定终端输出编码格式
这次是使用的这个方法展示解决了终端错误乱码显示的问题,具体解决步骤如下:
- 引用头文件
<windows.h> - 在 main 函数中调用下面的代码:
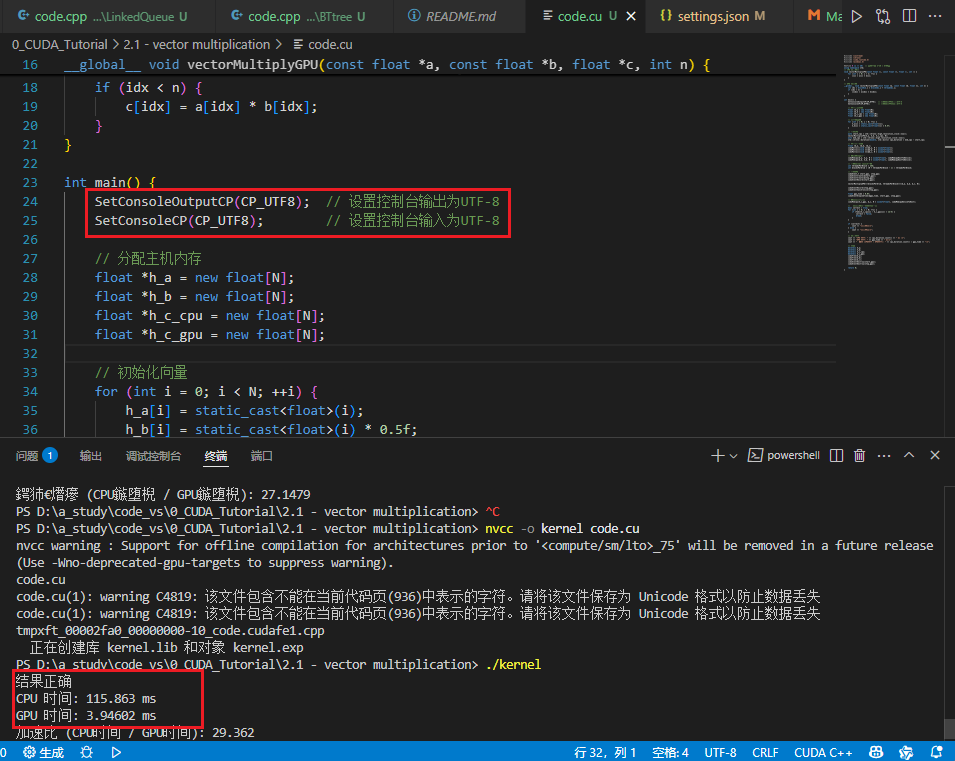
-
SetConsoleOutputCP(CP_UTF8); // 设置控制台输出为UTF-8 -
SetConsoleCP(CP_UTF8); // 设置控制台输入为UTF-8
-
编译运行,获得正确输出:
在.vscode设置文件添加默认编码格式指令
在 .vscode 文件夹中修改配置文件 settings.json
添加以下文段:
"terminal.integrated.defaultProfile.windows": "PowerShell",
"terminal.integrated.profiles.windows": {
"PowerShell": {
"path": "C:\\Windows\\System32\\WindowsPowerShell\\v1.0\\powershell.exe",
"args": ["-NoLogo"],
"icon": "terminal-powershell"
}
},
"terminal.integrated.setLocaleVariables": true,
"terminal.integrated.defaultEncoding": "utf8"保存
编译运行
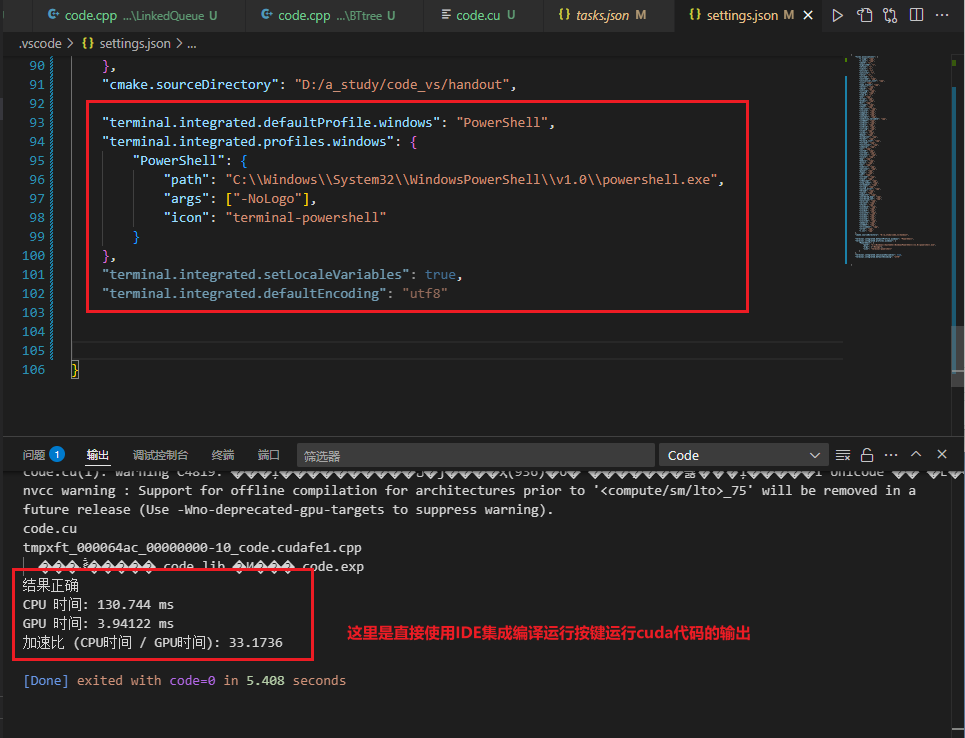
问题出现的底层逻辑
下面的内容摘自廖雪峰的个人博客,内容写得很清晰易懂,感谢其对我编码问题的解惑
UTF – 8 等系列编码
解决掉表层的问题并不是我们追求的最终结果,我们应该在解决问题的基础上去了解问题发生的底层逻辑,预防该类问题再次出现。
乱码显示错误涉及到计算机偏底层的字符编码问题。
在计算机内,我们输入的字符并不是按照我们所看到的形式去储存的,因为计算机的底层硬件就是二极管,只能表示1 | 0状态,并不能直接对应映射这些复杂的符号。如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295。
由于计算机是美国人发明的,因此,最早只有127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
因此,Unicode字符集应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是UCS-16编码,用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
现在,捋一捋ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000,注意字符'0'和整数0是不同的;
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | 01001110 00101101 | 11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
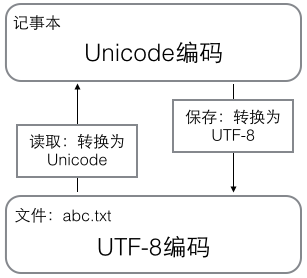
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
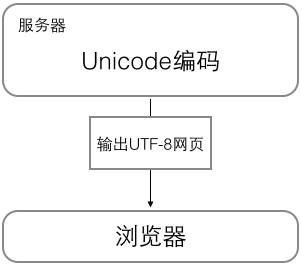
所以你看到很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。
Summary
在知道编码的问题后,我们不难知道,上面问题出现的原因大致是vscode上面的代码文件保存的编码格式与打开的编码格式(大概率是终端上默认的编码打开格式)不兼容,因此出现了乱码问题
而解决的问题就很简单了:
- 正确选择UTF – 8编码保存代码文本
- 指定正确的编码打开格式
以上方法均是依托于上面的points进行解决的
怎么样,探讨知道问题出现的底层逻辑,再去看解决问题的方案,是不是有一种恍然大悟的感觉。
恭喜你,有get到一个技术经验,又能从容面对未来的编程boss了!