前言
在经历了接近一个月没有方向、一头雾水的并行计算学习后,我终于意识实操对知识理解的重要作用【比赛那个不算实操,简直就像把一个才进入并行计算世界的小白兔放在一个地狱生存难度的草原上,然后叫小白兔去kill大Boss一样(小白兔能kiss到Boss就很不错了,哈哈哈)】
于是,在经历令人窒息的CUDA环境操作【mad,精准踩坑,害得我浪费了两三天的时间啥也没做,哈哈哈】,以及一头雾水、蹑手蹑脚、胆战心惊(实在是之前全是纸上谈兵,实战不是这里忘记参数传入的顺序,就是那里忘记关键字的书写…)的CUDA编程后,我…终于实现我设想的一个小CUDA程序!【角色突破!小白兔——>白兔!】
总结学习到的知识以及留下完成第一个CUDA程序一瞬的兴奋,
由此,记下下一篇文章以作留痕。
设想的简单程序实现的内容
Test_add(int *A,int *B,int *end,int size)在主机端初始化两个数组,并对其赋值
然后调用函数在设备端求和操作
最后将求和的结果输出
主体代码
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include<cuda_runtime.h>
#include <stdio.h>
#include <time.h>
#define Size 1024
__global__ void Test_add(int *A,int *B,int *end,int size)
{
int i = blockDim.x*blockIdx.x+threadIdx.x; // 获得线性【全局】索引
// 检查索引是否在处理范围内
if(i < size)
{
end[i] = A[i] + B[i];
}
}
int main()
{
// 错误检测
cudaError_t err;
clock_t start, end;
double cpu_time_used;
start = clock();
// 在这里放置您想要计时的代码
// 例如,可以是一些计算或处理任务
int a_h[Size] = {0};
int b_h[Size] = {0};
int end_h[Size] = {0};
for(int i = 0 ; i < Size ; i ++)
{
a_h[i] = i + 1;
b_h[i] = (i+1) * 2;
}
// // 打印a,b数组的数据
// for(int k = 0 ; k < Size ; k += 8)
// {
// printf("%d %d %d %d %d %d %d %d\n",a_h[k],a_h[k+1],a_h[k+2],a_h[k+3],a_h[k+4],a_h[k+5],a_h[k+6],a_h[k+7]);
// }
// for(int k = 0 ; k < Size ; k += 8)
// {
// printf("%d %d %d %d %d %d %d %d\n",b_h[k],b_h[k+1],b_h[k+2],b_h[k+3],b_h[k+4],b_h[k+5],b_h[k+6],b_h[k+7]);
// }
// int a_d[Size] = {0};
// int b_d[Size] = {0};
// int end_d[Size] = {0};
// 参考代码是声明的一个指针而不是数组
int *a_d;
int *b_d;
int *end_d;
int size_space = Size*sizeof(a_h[0]);
cudaMalloc((void **)&a_d,Size);
cudaMalloc((void **)&b_d,Size);
cudaMalloc((void **)&end_d,Size);
err = cudaMalloc((void **)&a_d, size_space);
if (err != cudaSuccess) {
printf("CUDA malloc error for a_d: %s\n", cudaGetErrorString(err));
return -1; // 终止程序
}
err = cudaMalloc((void **)&b_d, size_space);
if (err != cudaSuccess) {
printf("CUDA malloc error for b_d: %s\n", cudaGetErrorString(err));
cudaFree(a_d); // 清理已分配内存
return -1;
}
err = cudaMalloc((void **)&end_d, size_space);
if (err != cudaSuccess) {
printf("CUDA malloc error for end_d: %s\n", cudaGetErrorString(err));
cudaFree(a_d);
cudaFree(b_d); // 清理已分配内存
return -1;
}
cudaMemcpy(a_d,a_h,size_space,cudaMemcpyHostToDevice);
cudaMemcpy(b_d,b_h,size_space,cudaMemcpyHostToDevice);
err = cudaMemcpy(a_d, a_h, size_space, cudaMemcpyHostToDevice);
if (err != cudaSuccess) {
printf("CUDA memcpy error for a_h to a_d: %s\n", cudaGetErrorString(err));
cudaFree(a_d);
cudaFree(b_d);
cudaFree(end_d);
return -1; // 终止程序
}
int threadPerBlock = 256;
int blocksPerGrid = (Size + threadPerBlock - 1)/threadPerBlock; // 向上取整获取线程块数目
// 启动内核函数
Test_add<<<blocksPerGrid,threadPerBlock>>>(a_d,b_d,end_d,Size);
cudaDeviceSynchronize();
cudaMemcpy(end_h,end_d,size_space,cudaMemcpyDeviceToHost);
// __syncthreads();
// 错误的使用,线程同步应该在Block中使用
for(int k = 0 ; k < Size ; k += 8)
{
printf("%d %d %d %d %d %d %d %d\n",end_h[k],end_h[k+1],end_h[k+2],end_h[k+3],end_h[k+4],end_h[k+5],end_h[k+6],end_h[k+7]);
}
cudaFree(a_d);
cudaFree(b_d);
cudaFree(end_d);
end = clock();
cpu_time_used = ((double) (end - start)) / CLOCKS_PER_SEC;
printf("Time taken: %f seconds\n", cpu_time_used);
return 0;
}学到的一些重要的知识点和实践到的一些易错点
主机是【cpu】设备是【gpu】
上面的说法再去求证下
两个时间测量函数
实测:如果程序运行时间较短,测量时间误差较大
也正是由于代码简单和这两个测量函数的缺陷,我无法统计这个简单CUDA程序的加速比
用CUDA 的事件 API计算代码运行时间(特别适用于Kernel函数,较精确)
#include <stdio.h>
#include <time.h>
int main() {
clock_t start, end;
double cpu_time_used;
start = clock();
// 在这里放置您想要计时的代码
// 例如,可以是一些计算或处理任务
end = clock();
cpu_time_used = ((double) (end - start)) / CLOCKS_PER_SEC;
printf("Time taken: %f seconds\n", cpu_time_used);
return 0;
}C 语言中进行计时通常使用 clock() 函数(如果运行时间很少,可能不准确)
#include <stdio.h>
#include <time.h>
int main() {
clock_t start, end;
double cpu_time_used;
start = clock();
// 在这里放置您想要计时的代码
// 例如,可以是一些计算或处理任务
end = clock();
cpu_time_used = ((double) (end - start)) / CLOCKS_PER_SEC;
printf("Time taken: %f seconds\n", cpu_time_used);
return 0;
}实践:简单串行程序运行时间比CUDA程序更快
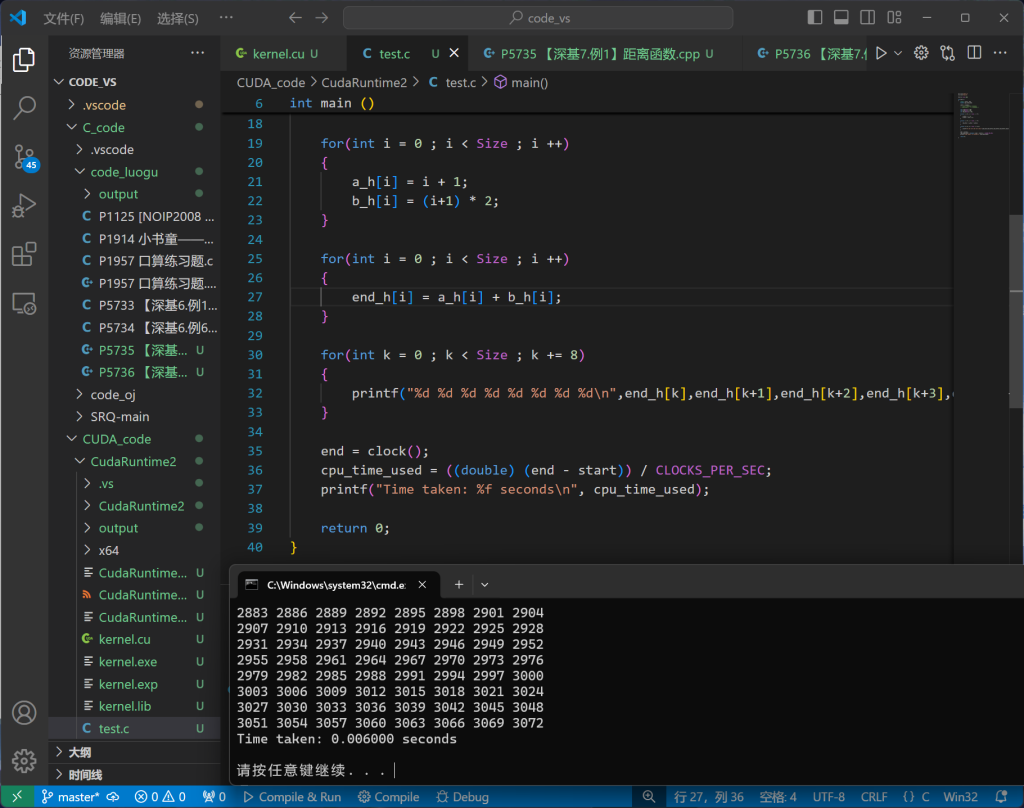
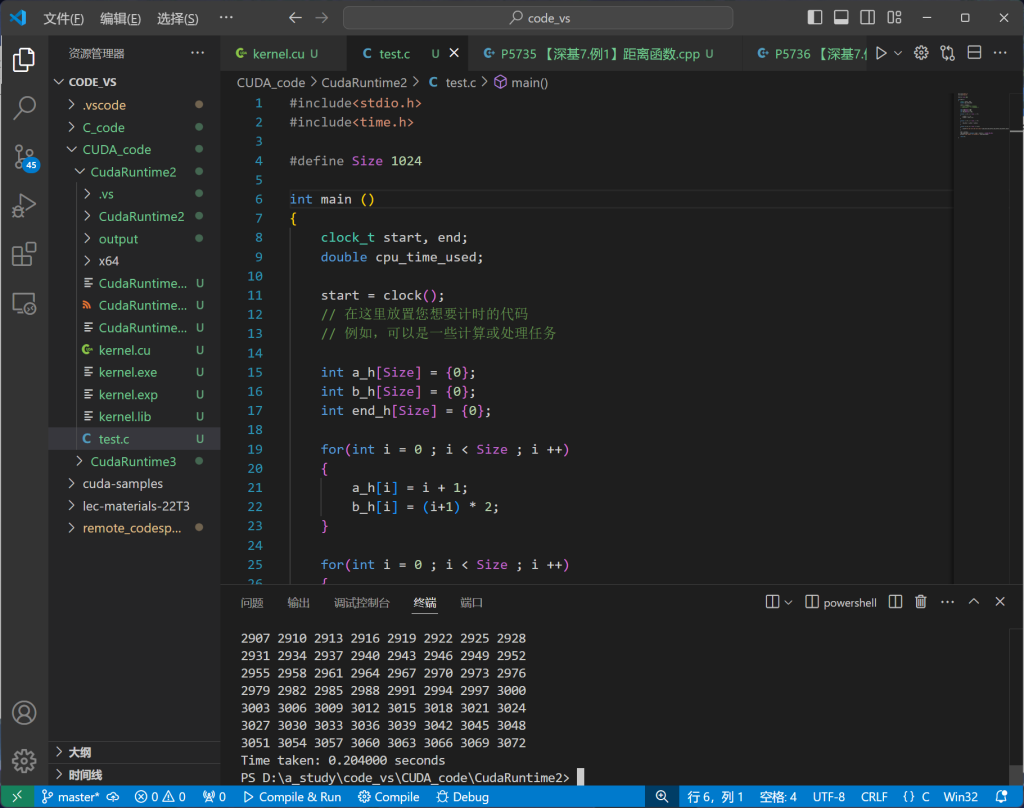
前者为串行程序,后者为CUDA程序
均使用time.h中的函数进行时间测量
CUDA函数编写的顺序
- 先编写C程序的框架
- 然后在要并行计算的部分做下标记,编写并行计算的函数【一般是global函数】
- 准备并行计算的数据
- 数据的空间划分
- 数据的装载
- 核函数的运行
- 同步操作
- 划分空间的释放
__global__函数【核函数/kernel函数】
__global__函数是在CPU端执行的函数__global__函数会被所有的线程调用,是全局可访问函数__global__函数可以访问全局内存、共享内存和常量内存
痛苦考点:硬件中哪些内存,不同内存对应在硬件的哪个位置?
【阶段小结】
一个GPU中包含…
阅读下面文章后继续进行总结
【GPU】深入理解GPU硬件架构及运行机制-CSDN博客)
global中需要包含线程索引计算变量,以此来分配不同线程需要执行的操作
比如原码中的:
int i = blockDim.x*blockIdx.x+threadIdx.x;
还可以设置步长进行更复杂的任务分配【例:矩阵乘】
数据的准备
变量的声明
注意:
一定不要直接声明数组变量作为传入设备端的参数!应该用指针变量取而代之!!
后面补充原因:
声明数组变量作为参数传递的时候,cudaMemcpy函数运行错误
CUDA memcpy error for a_h to a_d: invalid argument错误的原因是在主机端声明的数据在编译器的强制要求下必须要知道具体的数组大小,因此声明的数组就是一个已知大小的静态数组,而这个静态数组的指针是指向主机端地址 【指向的地址已经确定】,因此不能再使用cudaMalloc为其分配一个设备端的地址
为什么修改成指针变量就可以了呢?
因为指针可以先初始化不赋值,这样传入cudaMalloc的指针是纯粹的,可以为那个指针变量分配设备端的空间
【收获】
下次要给设备端传入数组数据的话,在主机端不能声明数组变量,而应该声明一个指针变量
空间的划分
cudaMlloc();
传递两个参数
第一个:(void **var1)
第二个:(int size_memory)
第一个参数,一般是在主机声明一个指针int *var1;
然后传入参数&var1
第二个参数,一般是用num*sizeof(example)
例如:inr Size = const_num * sizeof(float);
数据的装载
cudaMemcpy();
传递四个参数:
第一个:(Type **var1)
第二个:(Type **var2)
数据从var2传输到var1【和rust里面的有个函数很像】
第三个:(int size_memory)
装载数据的大小,一般是用num*sizeof(example)
第四个:数据传输方向的关键字cudaMemcpyDeviceToHostcudaMemcpyHostToDevice
核函数的运行
Kernel<<<(int )blocksPerGrid,(int )threadPerBlock>>>(The_vars_needed);
需要注意的点:
- 执行配置的关键符号是<<<>>>,注意,左右一定是三个小三角号!!!【踩过坑】、
- 执行配置的变量一定要是int类型!
同步操作
cudaDeviceSynchronize();
在 CUDA 程序中,核心操作(如核函数调用)是异步执行的,这意味着 CPU 代码会继续执行,而不会等待 GPU 完成核心操作。cudaDeviceSynchronize() 会等待所有先前启动的核心操作完成。防止后面计算的数据不齐
划分空间的释放
cudaFree(var);