BY ziyang
0 字符与整数的联系 ——ASCLL 码
0.1 ASCLL 需要记住的几个点
- 数字 0~9 对应 48~57
- 26 个英文字母
- 65 为 A
- 97 为 a
- 大小写之前差 32(不知道与 32 进制是否有关系,哈哈)
0.2 字符与数字之间怎么进行转化?
注意:字符要用” 进行分隔!!
- 强制类型转化
附,利用此原理手搓的 ASCLL 码表:
由于有些符号电脑不能显示,故出现下图样式
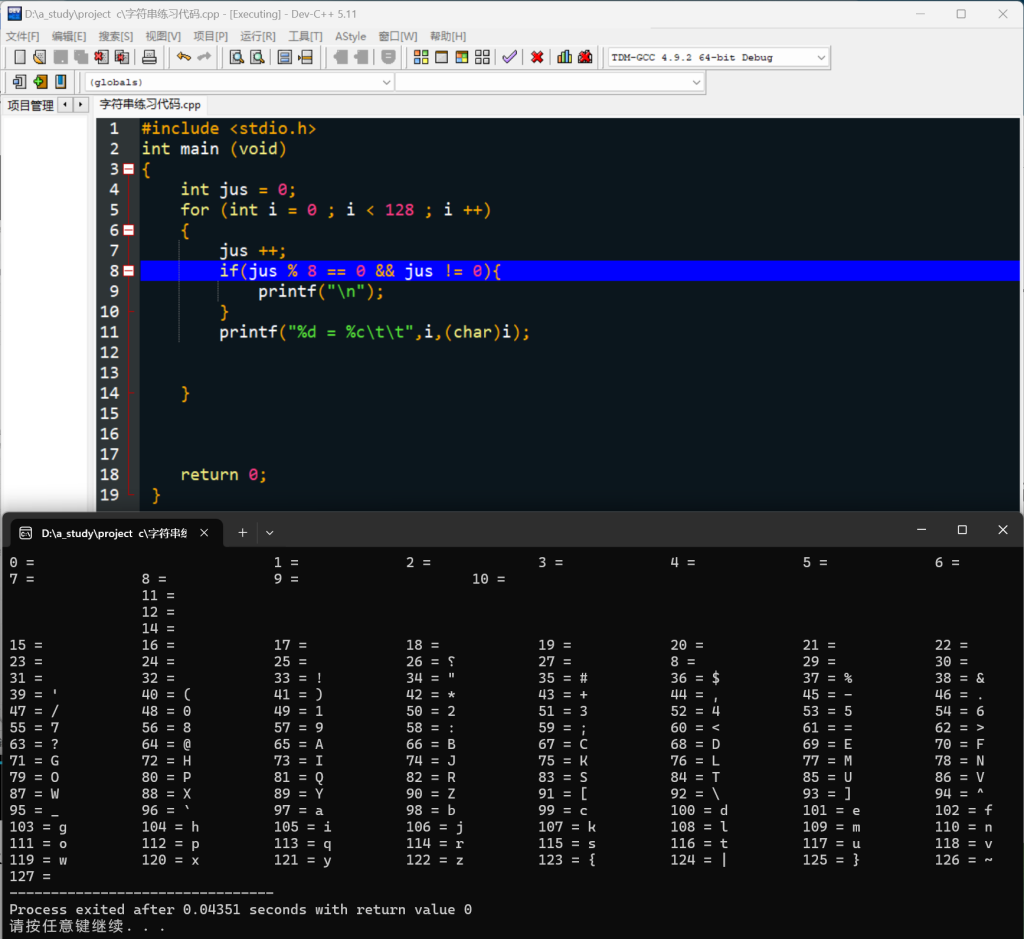
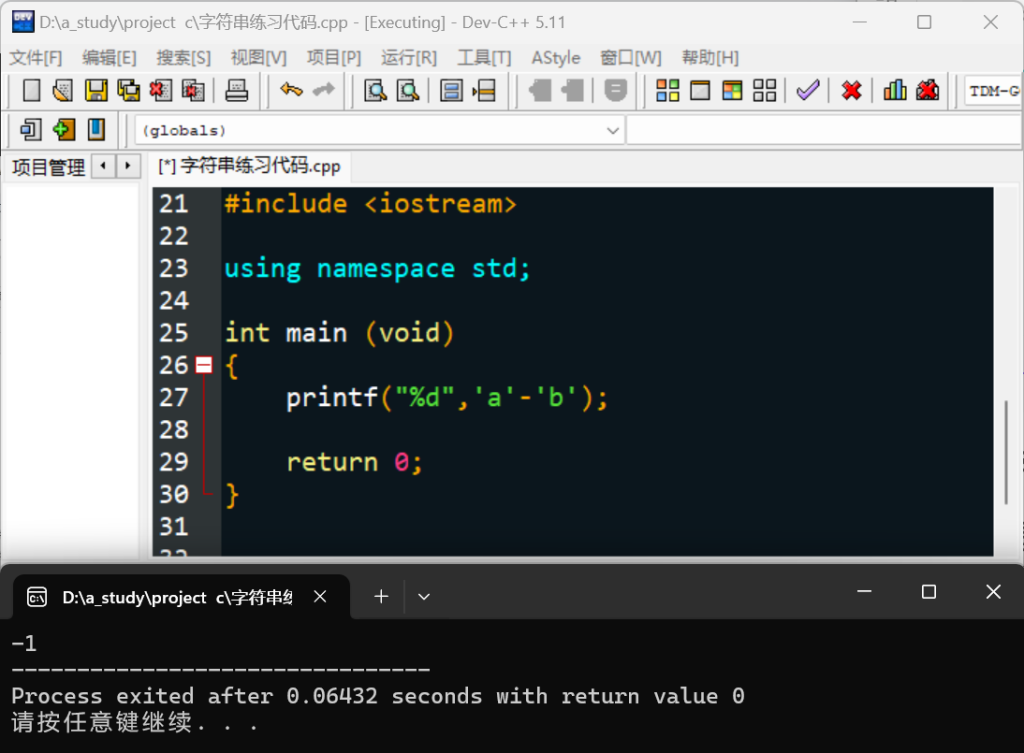
- 字符间的运算:
会把字符自动转化为数字,再进行数字间的运算,例如:
可以这样去理解 ——>char 本身是储存一个整数,但是在输出的时候,对应占位符输出
1 字符数组
1.1 基本定义
字符串就是字符数组结尾加上一个空字符”\0″。
新概念:
空字符 ——”\0“我们可以用字符串来初始化字符数组,但是值得注意的是,每个字符串数组结尾都会暗含一个”\0″,也就意味着此时字符数组长度比 “明面上的” 字符长度要多 1。
附:字符是用” 引起来,而字符串要用 “” 引起来
例如:
”Hello World“一共是 11 个字符。
用其初始化 char string [] 之后,得到的字符串的长度为 11 个字节。
但是 char string [] 的数组长度【不知道专业名是否叫长度】是 12 = 11 + 1。
1.1.1 字符串字面量
用双括号括起来的内容被称为字符串字面量,也叫做字符串常量,会自动添加 “/0”
注意:
在字符串字面量之前如果没有间隔,或者用空白字符分隔,C 语言会视为串联起来的字符串变量

1.2 字符数组的初始化
几种不同的初始化:
小思考:
下面是含有问题的图片:

是的
附:二维字符数组的初始化
在 C 语言中,二维字符数组通常用于存储字符串或字符矩阵。二维字符数组的初始化可以在声明时完成,也可以在声明后通过循环或显式赋值完成。以下是一些初始化二维字符数组的例子:
静态初始化(在声明时初始化)
在声明二维字符数组时,可以直接在大括号内初始化数组的元素。每个子数组(即每一行)的元素也应该用大括号括起来。
动态初始化(声明后初始化)
如果你需要在声明后初始化二维字符数组,可以使用循环或显式赋值。
注意事项
- 在静态初始化时,如果某个子数组的元素少于声明的列数,编译器会自动用空字符(
\0)填充剩余的位置。 - 如果你初始化的字符串长度超过了数组的列数,编译器会截断多余的部分。
- 在 C 语言中,字符串以空字符(
\0)结尾,所以在初始化包含字符串的二维字符数组时,不需要显式添加空字符,编译器会自动处理。 - 在动态初始化时,如果数组的某一行没有完全初始化,剩余的位置会被初始化为垃圾值(未定义的值),所以通常需要显式地初始化每一行的每一个元素。
二维字符数组在 C 语言中常用于处理文本数据,如字符串数组或简单的文本矩阵。
2 字符数组的使用
2.1 字符数组的输入输出
注意:
- 什么时候字符数组的输入需要加 &?
附:puts 函数
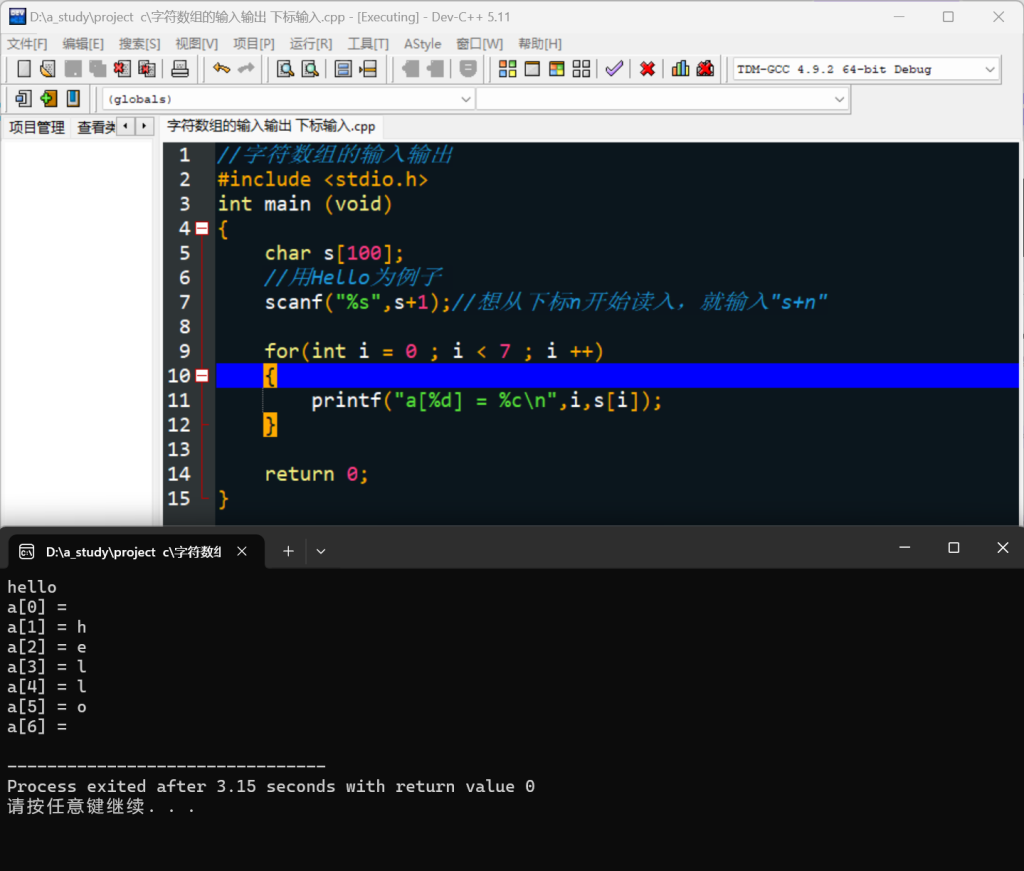
2.2 下标改变的输入:
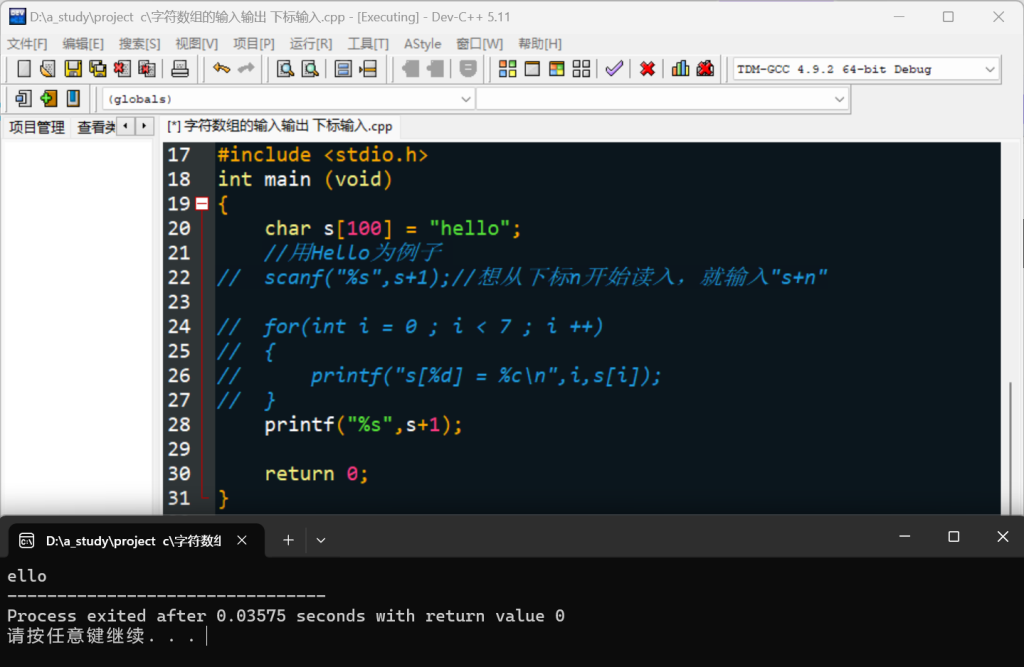
同理,对指定下标的输出:
2.3 字符串整行输入
输入字符串时,遇到空格或者回车就会停止(停止一次输入)
例如:
- ** 输入字符串时,遇到空格或者回车就会停止(停止一次输入),那么怎么才能连续读入一行字符呢?【即遇到空格不停止】
附:scanf 的返回值
、在 C 语言中,scanf 函数用于从标准输入(通常是键盘)读取格式化输入。scanf 函数的返回值是成功读取的输入项的数量。如果输入不符合预期的格式,scanf 将停止读取并返回已经成功读取的项数。
例如,如果你使用 %d 来读取一个整数,而用户输入了一个字母,scanf 将不会读取该字母,并且返回 0,因为它没有成功读取任何整数。
scanf 函数的原型如下:
这里的 format 是一个格式字符串,它指定了期望输入的格式。其余的参数是指向变量的指针,这些变量将存储输入的值。
返回值的具体含义如下:
- 如果成功读取至少一个项,返回读取的项数。
- 如果没有成功读取任何项(例如,因为输入不符合格式),返回
EOF(通常定义为 -1)。 - 如果发生读取错误(例如,由于输入 / 输出问题),返回一个负值。
使用 scanf 时,通常需要检查其返回值,以确保输入是有效的。例如:
在实际编程中,为了更安全地处理输入,推荐使用 fgets 函数配合 sscanf 函数,或者使用 fgets 函数配合字符串解析函数,这样可以更好地控制输入过程,并避免缓冲区溢出等安全问题。
在 c++ 中的读入函数:
- gets 函数【C 中可用】
注意:
从 C11 标准开始,gets 函数已经从 C 语言中移除,原因是它允许输入超过缓冲区大小的字符串,这会导致缓冲区溢出,可能引起程序崩溃或安全漏洞
但是部分编译器(如 Devc++)没有严格遵守 C11 标准,因此允许 gets 函数的使用
- fgets 函数【C 中可用】
注意:
fgets 函数会读入输入流首位 / 末尾的回车符号
因此使用 fgets 函数之前需要特别注意是否会读入回车符
注意:
在 fgets (s,100,stdin); 中 s 表示读入字符串写入的目标数组,100 表示最多读取的字符串长度,stdin 表示从哪个文件中读入,一般都是从文件 stdin 中读入(stdin 是系统中的一个变量,已经被定义好了)
附:
使用 fgets 函数读入字符串后计算长度的时候,记得判断并取消末尾读入的 \n
- cin.getline 函数【读入数组】
- getline 函数【读入 string】
注意:
getline (cin,s) 中固定第一个为 cin 第二个传递的为 string 数组
2.4 遍历字符串数组中的字符
同理数组的遍历输出:
重点 —— 循环结束的条件,引用 strlen () 函数
但是由于 strlen () 函数在条件判断里面,所以会循环 n 次,这样程序运行的时间就会增加,效率就会很低
修改:
或者更简洁一点:
3 字符串数组

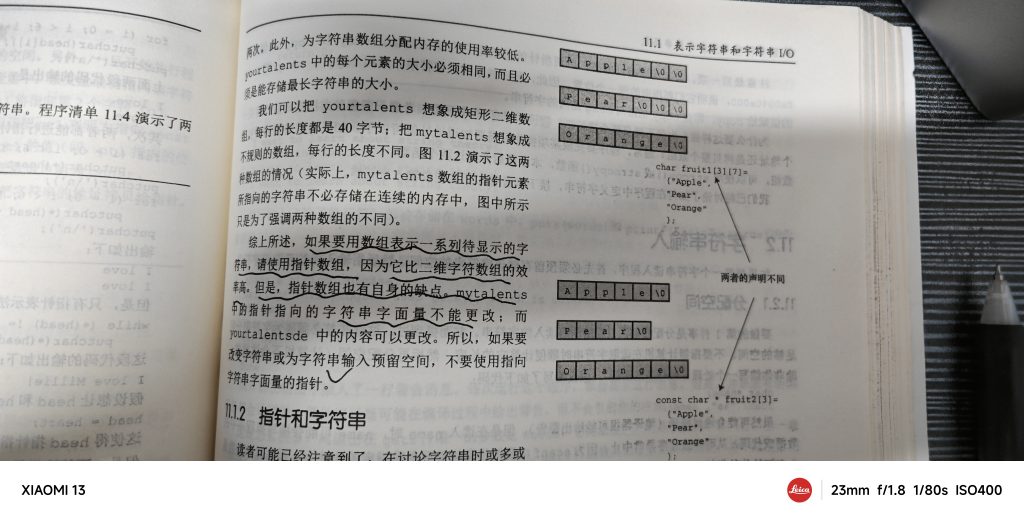
字符串数组分为两类:
- 指针 * 数组
指针数组很好理解,每一个数组空间里面都储存着一个字符串 - 数组 * 数组
相当于一个二维字符串数组,每一 “维” 都对应一个字符数组
二者的区别:
同字符串数组的区别
4 相对常见的几个字符串函数
4.1 strlen (s) 函数
// 作用,求字符串的长度(不包含 “ \n”)
strlen (a,b) 等价函数:
链接:程序编译集锦 P11
附加
这段代码使用 fgets 函数从标准输入(stdin)读取最多 11 个字符(第 12 个位置留给空字符 \0)到字符数组 ch 中,并计算字符串的长度。但是,当你输入 “a” 并按下回车键时,fgets 会将回车符(换行符)也读入到数组中。因此,如果你输入的是单个字符 “a” 后紧接着按下回车键,数组 ch 将包含以下字符:
这里:
'a'是你输入的字符。'\r'是回车符,如果你在 Windows 系统上运行程序,它可能会被包含。'\n'是换行符,这是大多数 Unix/Linux 系统上的行结束符。'\0'是字符串结束的空字符。
strlen 函数计算从字符串开始到第一个空字符之间的字符数量。在这个例子中,strlen 将计算 'a' 和 '\0' 之间的字符数量,但不包括回车符和换行符,因为它们位于空字符之前。
因此,如果你的系统在输入时包含回车符,那么 strlen 的返回值将是 2,因为 'a' 和 '\0' 之间有一个回车符。
如果你希望 strlen 只计算实际输入的字符而不包括回车符和换行符,你可以在调用 strlen 之前手动移除这些字符。例如:
这段代码在计算长度之前检查并移除字符串末尾的回车符和换行符,这样 strlen 就会返回实际输入的字符数量。
4.2 strcmp (a,b) 函数
比较两个字符串的大小(按字典序比较)。a > b 返回 - 1,a < b 返回 1,a = b 返回 0;
注意:是后面的与前面的进行(字符序)比较
附:字典序与贪心排序?
AI 解释:

4.3 strcpy (a,b) 函数
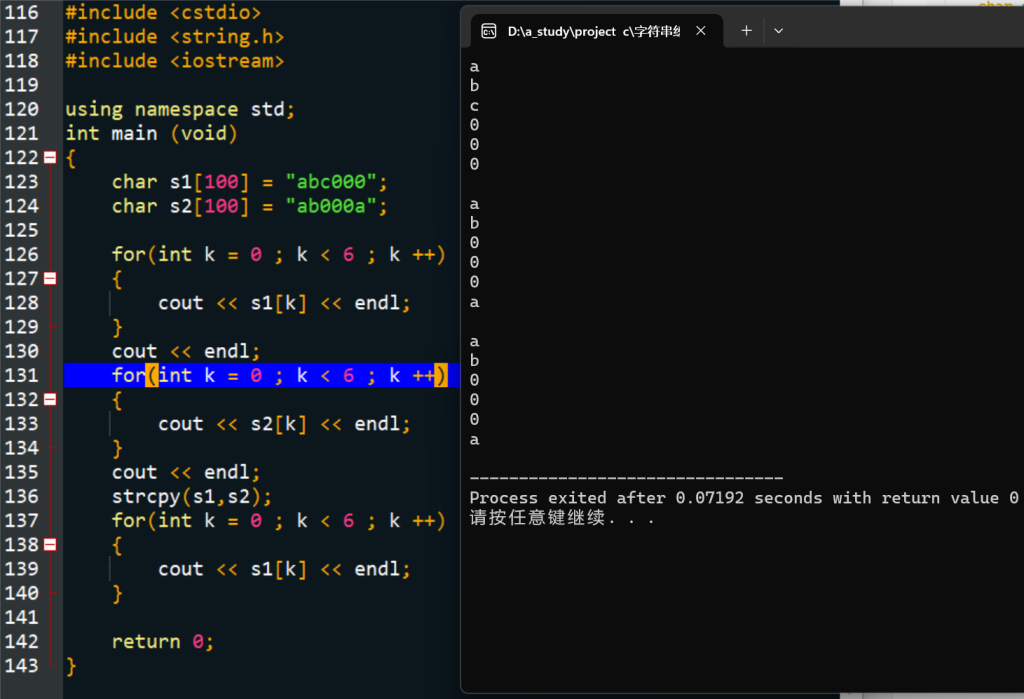
这个记错了吗?怎么回事???
把后面的字符串 b 复制给前面指定位置的 astrcpy(s + len - 3, temp);
比如这一句,就是将 temp 字符数组从 s[s + len - 3] 位置开始复制到 s 数组中
复制的时候要注意空间是否重叠,如果是,则不能进行复制
如:(0 表示没有输入)
a[6] = abc00;
b[6] = ab00a;
这样就不能进行 copy
后面得修改一下语言,感觉描述语言有问题

4.31 strncpy (); 函数
- 函数定义和功能
strncpy函数是 C 语言中的一个字符串处理函数,用于将一个字符串的一部分复制到另一个字符串中。它的函数原型定义在<string.h>头文件中,形式如下:char* strncpy(char* destination, const char* source, size_t num);。- 其主要功能是把
source指向的字符串中最多num个字符复制到destination指向的数组中。
- 参数说明
destination:这是目标字符串,是一个字符数组,用于存储复制后的内容。它应该有足够的空间来容纳复制的字符以及可能的字符串结束符'\0'。source:这是源字符串,是一个常量字符数组(由const修饰,表示内容不被函数修改),是要被复制的字符串。num:是一个无符号整数类型(size_t)的参数,表示最多要从source复制到destination的字符个数。
- 返回值
strncpy函数返回目标字符串destination的指针,这使得它可以在一个表达式中被链式调用或者方便地进行后续操作。
- 示例代码
- 以下是一个简单的示例,展示
strncpy函数的基本用法:
#include <stdio.h> #include <string.h> int main() { char source[] = "Hello, World!"; char destination[20]; strncpy(destination, source, 5); destination[5]='\0'; // 手动添加字符串结束符 printf("%s\n", destination); return 0; }- 在这个示例中,
source字符串包含"Hello, World!"。strncpy函数将source的前 5 个字符复制到destination中。由于strncpy函数不会自动在destination末尾添加'\0'(除非source中的字符数小于num),所以需要手动添加字符串结束符'\0',这样才能正确地使用printf函数输出destination中的字符串,程序将输出Hello。
- 以下是一个简单的示例,展示
- 注意事项
- 如果
source中的字符数小于num,strncpy会在复制完source的字符后,在destination中剩余的位置填充'\0',直到复制了num个字符。例如:
#include <stdio.h> #include <string.h> int main() { char source[] = "abc"; char destination[10]; strncpy(destination, source, 5); printf("%s\n", destination); return 0; }- 这个程序会输出
abc\0\0(\0表示不可见的字符串结束符),因为source只有 3 个字符,strncpy在复制完这 3 个字符后,会在destination中填充 2 个'\0',以达到num = 5的要求。 - 如果
num大于source的长度但小于destination的长度,destination中多余的部分不会被初始化(除非手动进行处理),这可能会导致一些未定义的行为,例如在后续操作中误将这些未初始化的字符当作有效字符处理。 - 另外,
destination必须有足够的空间来容纳复制的字符,否则可能会导致缓冲区溢出,这是一个常见的安全漏洞,可能会使程序崩溃或者被恶意攻击。
- 如果
4.4 strcat (); 函数
- 函数原型为
char *strcat(char *dest, const char *src);。- 在下面这个例子中,
strcat函数将字符串t复制到字符串s的末端。它首先找到s的末尾(也就是当前s中最后一个字符后面的位置,这个位置是由'\0'来标识的,strcat会从这个'\0'位置开始复制),然后将t中的字符逐个复制到s中,直到遇到t中的'\0'结束符,最后在新的s末尾也会保留这个'\0'结束符。并且strcat函数返回指向dest(也就是s)的首地址,这样就满足了题目中要求的功能。 - 不过要注意,使用
strcat函数时,必须确保dest所指向的数组有足够的空间来存储连接后的字符串,否则会导致缓冲区溢出。
- 在下面这个例子中,
- C++ 语言中的
std::strcat函数(在<cstring>头文件中)- C++ 兼容 C 标准库,所以在 C++ 中也可以使用
strcat函数来实现类似的功能。 - 另外,在 C++ 中更推荐使用
std::string类来操作字符串,std::string类提供了append方法来实现类似的字符串连接功能。 - 例如:
cpp #include <iostream> #include <string> int main() { std::string s = "Hello, "; std::string t = "World!"; s.append(t); std::cout << s << std::endl; return 0; }
- C++ 兼容 C 标准库,所以在 C++ 中也可以使用
4. strstr () 函数
函数原型:char *strstr(const char *haystack, const char *needle);。其中 haystack 是要在其中查找的主字符串,needle 是要查找的子字符串。
功能:用于在一个字符串中查找指定字符首次出现的位置。它返回一个指向该字符第一次出现位置的指针,如果找不到指定字符,则返回 NULL。
示例代码:
4. puts () 函数
puts 函数属于系列的输入输出函数
(也就是说头文件 #include 中就包含这个函数
作用:
puts () 函数只显示字符串,而且自动在显示的字符串末尾加上换行符

4. sprintf 函数
sprintf 函数是 C 语言标准库中的一个函数,用于将格式化的数据写入字符串。它的原型定义在 stdio.h 头文件中,其功能类似于 printf,但 printf 将格式化的数据输出到标准输出(通常是屏幕),而 sprintf 将数据写入一个字符串。
sprintf 函数的原型如下:
参数说明:
str:指向字符数组的指针,用于存储生成的格式化字符串。format:格式控制字符串,它指定了后续参数如何被格式化。...:可变参数列表,其个数和类型依赖于格式控制字符串。
返回值:
- 成功时返回写入的字符数,不包括结尾的空字符
\0。 - 失败时返回一个负数。
格式控制字符串 format 可以包含普通的字符和特殊的格式化占位符。普通的字符会原样输出,而格式化占位符会被相应的参数替换。格式化占位符通常的形式是 % 后跟一个或多个格式说明符,例如:
%d:替换为一个十进制整数。%f:替换为一个浮点数。%s:替换为一个字符串。%c:替换为一个字符。%x或%X:替换为一个十六进制整数(小写或大写)。%o:替换为一个八进制整数。%p:替换为一个指针的值,通常显示为十六进制。
除了类型说明符,还可以指定宽度、精度、长度修饰符和标志位来控制输出的格式。例如:
%5d:整数至少占用 5 个字符的宽度,如果不足则用空格填充。%.2f:浮点数打印到小数点后两位。%05d:整数至少占用 5 个字符的宽度,如果不足则用 0 填充。%-5s:字符串至少占用 5 个字符的宽度,如果不足则用空格填充,但左对齐。
下面是一个使用 sprintf 的示例:
在这个例子中,sprintf 将整数 value、浮点数 fvalue 和字符串 text 格式化后存储到 buffer 中,然后通过 printf 函数输出这个格式化后的字符串。
安全注意事项:
- 使用
sprintf时需要确保目标字符串str有足够的空间来存储所有格式化后的字符,包括结尾的空字符\0,否则可能会导致缓冲区溢出。 - 为了避免缓冲区溢出的风险,推荐使用
snprintf函数,它允许指定目标缓冲区的最大长度,从而防止溢出。
snprintf 函数的原型如下:
这里的 size 参数指定了目标缓冲区的最大长度,snprintf 会确保不会写入超过这个长度的字符,包括结尾的空字符。如果格式化后的字符串长度超过了 size,则只写入 size - 1 个字符,并在最后加上空字符 \0。返回值是如果没有发生截断,它将返回写入的字符数(不包括结尾的空字符),如果发生截断,则返回所需的总长度(不包括结尾的空字符)。
5 标准库 string
可变长的字符序列(是一个动态分配的数组),比字符数组更加好用。但是需要引入头文件:可以的
可以动态地把两个字符串拼在一块儿?
#inlcude <string>
5.1 定义和初始化
5.2 部分函数
5.2.1 .empty () 函数
注意,是’.’+ 函数!!
用来判断字符串是否为空
如果是空字符串的话就返回 “true/1”,如果不是的话,就返回 “false/0“【返回一个布尔值】
5.2.2 .size () 函数
和 strlen () 函数的效果相同,返回字符串的长度
但是.size () 函数是储存了变量的,不需要循环整个数组,所以运行效率大于 strlen ()
strlen () 函数本质上会循环整个字符数组,可以参考之前的等价代码
![[Pasted image 20240913101236.png]]
5.2.3
5.2 输入和输出
string 可以只能用 cin 读入,不能用 scanf 读入
string 可以用 cout 输出,也可以用 printf 输出,但是输出的格式会有变化【同理,也可以用 puts】
注意:
- 使用 printf (“% d”,s1.c_str ()); 进行输出,其中的 s1.c_str () 表示调用一个
<string>中的 xx 成员函数,返回存储 s1 字符串的字符数组的首地址(也可以看作这个函数将 (string) s1 转化为 (字符数组) s1,进而输出 s1),进而进行输出 - 注意字符数组和 string 的读入函数和输出函数的区别
5.3 运算
5.3.1 关系运算
string 类型的变量可以直接进行部分关系运算,例如
< > <= >= == !=
按照字典序进行比较
但是字符数组只能运用 strxx () 函数进行运算
![[Pasted image 20240913110143.png]]
5.3.2 赋值运算
string 的变量可以直接进行赋值运算,例如:
5.3.3 字符串”+“运算、“+=” 运算
直接将字符串拼接在一起
附加:字面值和 string 对象相加:
做加法运算时,字面值和字符都会被转化成 string 对象,因此直接相加就是把这些字面值串联起来string s1 = "hello",s2 = "world"; // 在 s1 和 s2 中都没有标点符号string s3 = s1 + "," + s2 + '~!';
当把 string 对象和字符字面值以及字符串面值混在一条语句中使用时,必须确保每个加法运算符的两侧的运算对象至少有一个是 string
–> 因为只有 string 变脸才能够进行直接加法运算【简单运算符的一方是 string 变量,则整个运算就都会变成 string 变量的运算(同整型变量与浮点数运算时数据类型的转化一样)】string s4 = s1 + ","
// 正确:把一个 string 对象和一个字面值相加string s5 = "hello" + "."
// 错误,两个运算对象都不是 string 变量string s6 = s1 + "," + "world"
// 正确:每个加法运算都有一个运算对象是 string 参数string s7 = "hello" + "," + s2
// 错误:不能把字面值直接相加,运算是从左到右进行的
5.3.4 处理 string 变量中的字符
可以直接把 string 当作字符数组处理
也可以利用 C++ 所特有的函数(范围遍历)
注意,这个函数中的 “c” 相当于是一个储存量,每次循环把数组元素储存到 “c” 里面,所以无法通过对 “c” 的运算来改变字符数组 string
那怎么完成上面的设想呢?for(char &c : s) cout << c << endl;
在 c 前加上一个取地址符(原因目前不知。感觉像是把 c 改成一个指针了)
附:汉字的字符串储存
前言:问题来源于我做哈夫曼编码和译码实训的时候,题目要求输入一段英文或中文。然后对其中的英文或中文进行检索,才能计算出相应的哈夫结点权值,构造哈夫曼树求哈夫曼编码。
![[Pasted image 20240922142501.png]]
我们可以发现,中文占两个字节,而 char 类型是一个字节长度的;因此,它的长度与 char 类型数据并不符合。这也就意味着我们不能像 char 类型一样简单操作中文字符。
问题总有解决的办法,像 GB2312 这些大多汉字编码,典型的用 2 个字节来表式大多数常用的中文汉字,最多可以表式 65536 个汉字,(同时:字符在数组中的存储是连续的)
所以我们可以用一个 char 数组实现对中文字符的操作,例如:
一、想要存入一个或多个中文:
二、对其中的一些中文取出:
三、判断两个中文是否相等:
当然,如有需要也可以同时存入英文和中文;
总之,char 类型一个字节用一个 % c 就可以表示,中文需要两个 % c% c 才能表示.
一些字符串函数的代码实现
strcat 函数:
strstr 函数:
高级的 strcpy 函数
无 string 头文件实现版本:
[!note] 重点
关键在于 len 读取后重置 t 指针位置
删除指定字符函数
由此可以拓展出删除指定字符串的函数:






